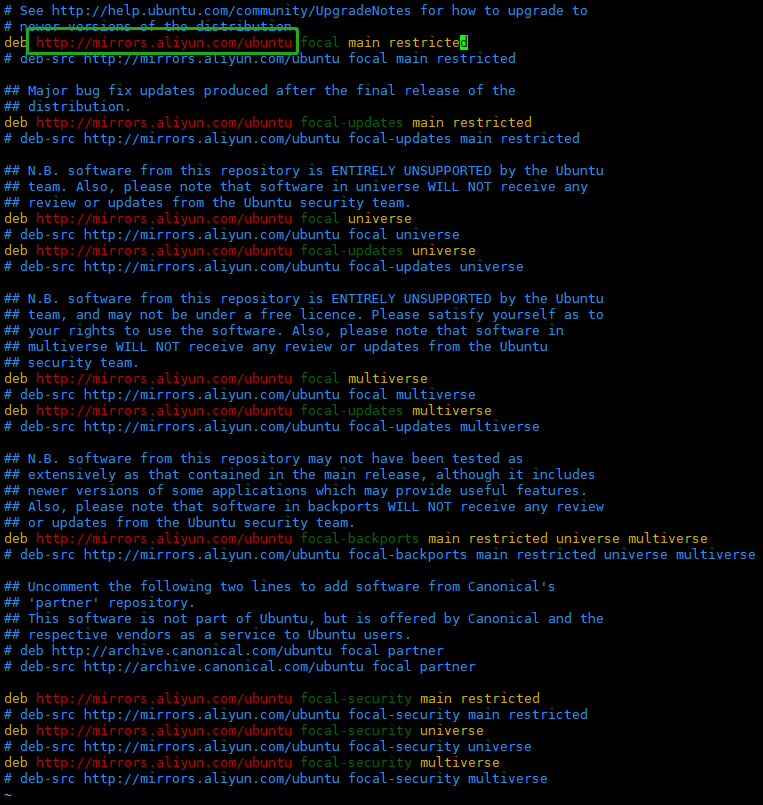
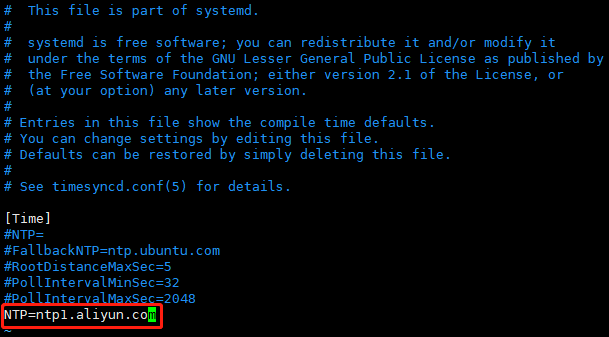
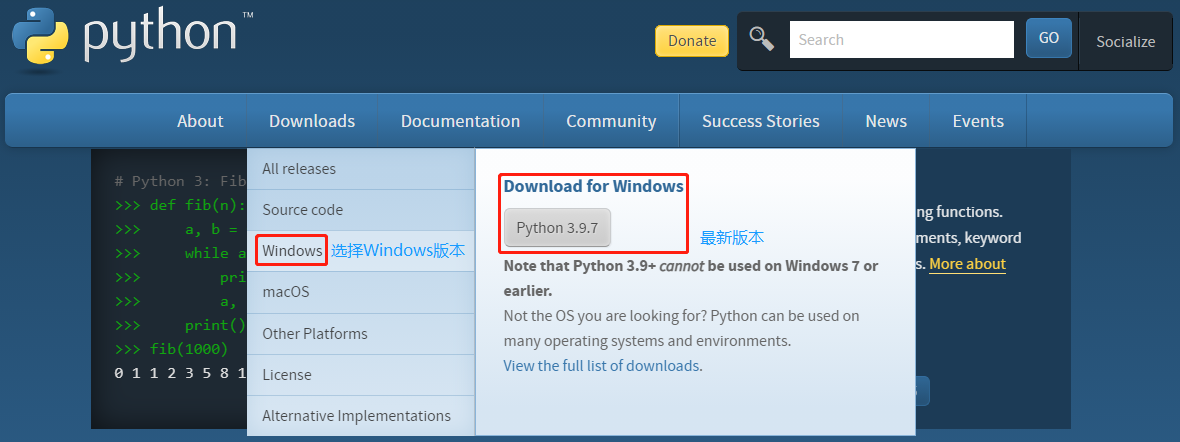
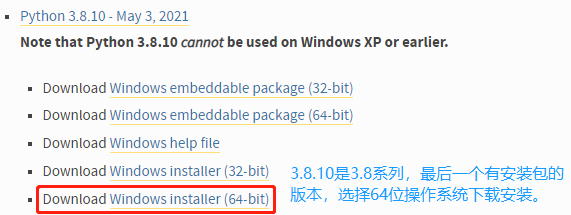
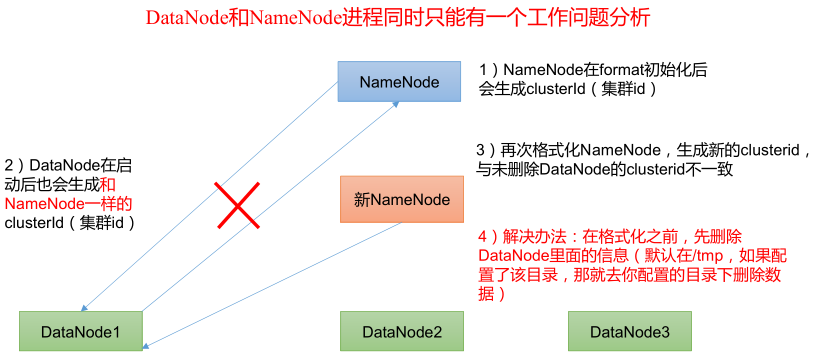
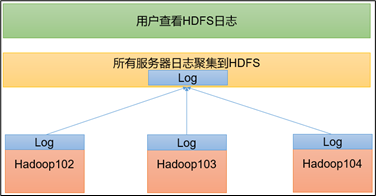
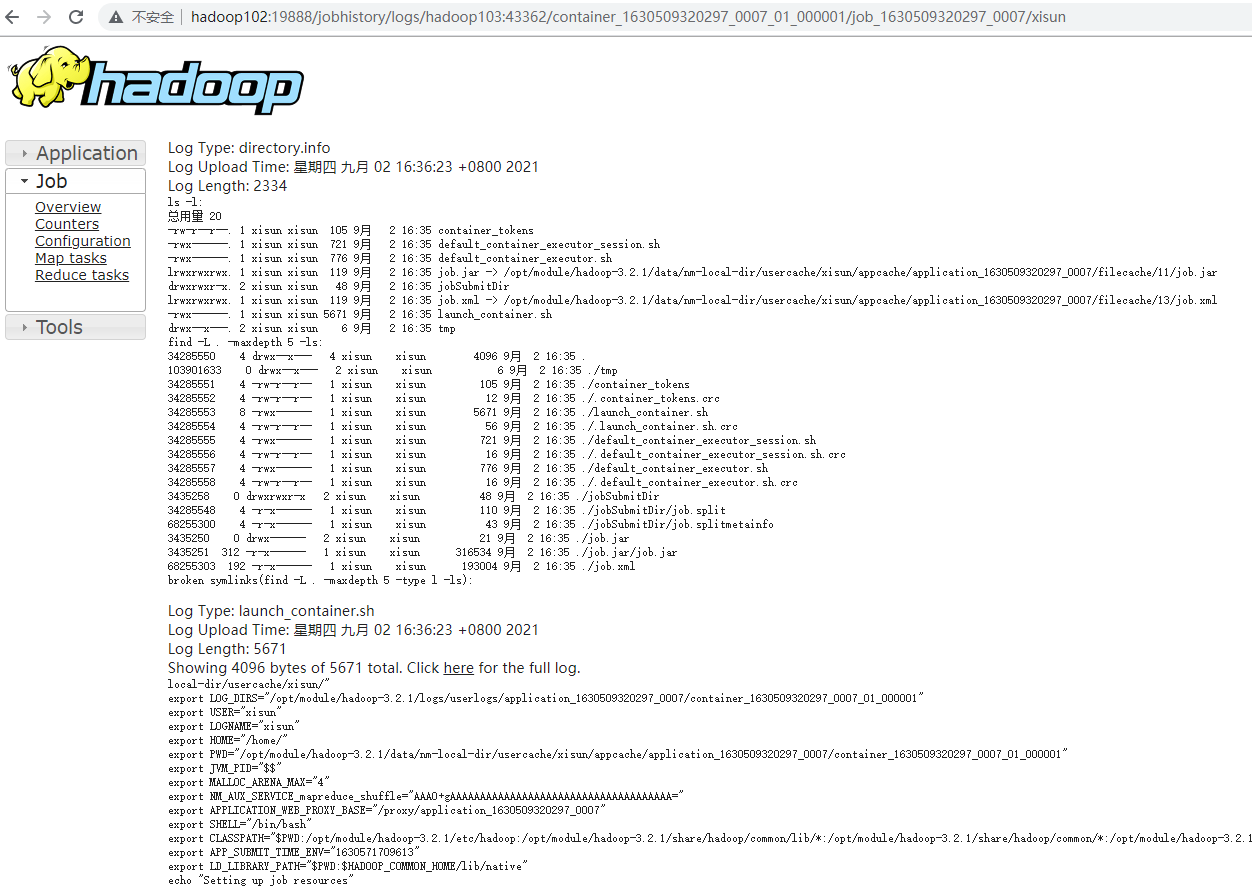
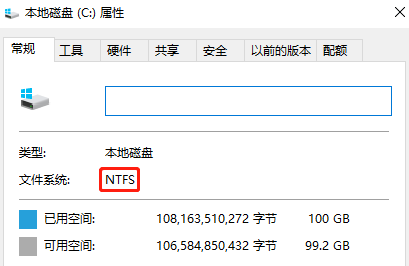
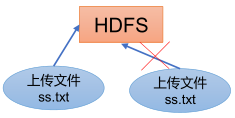
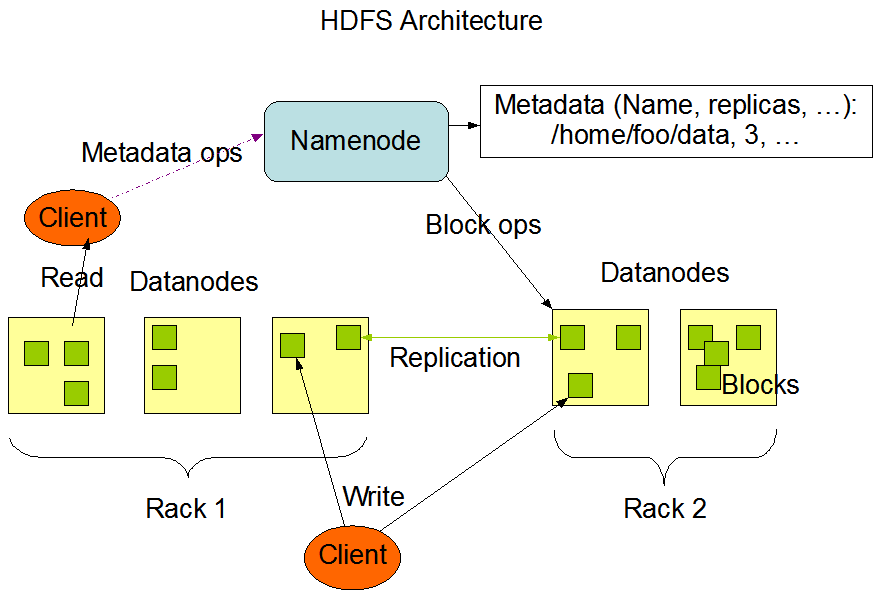
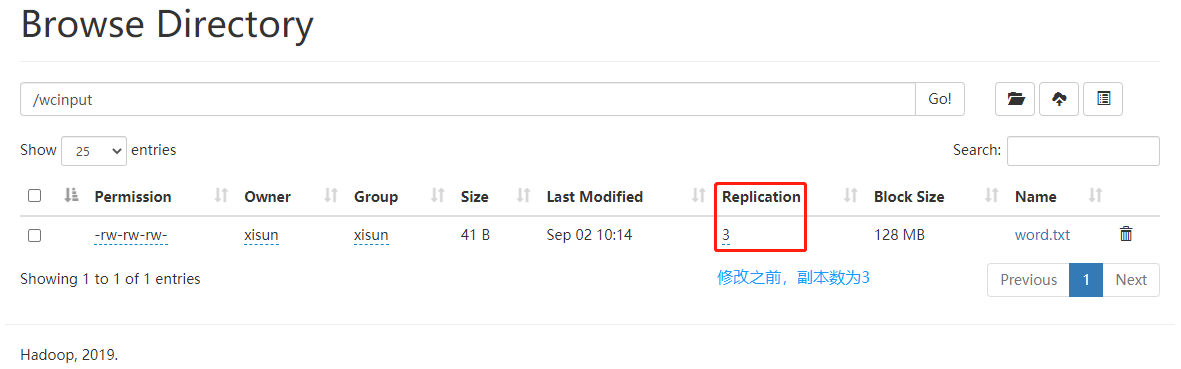
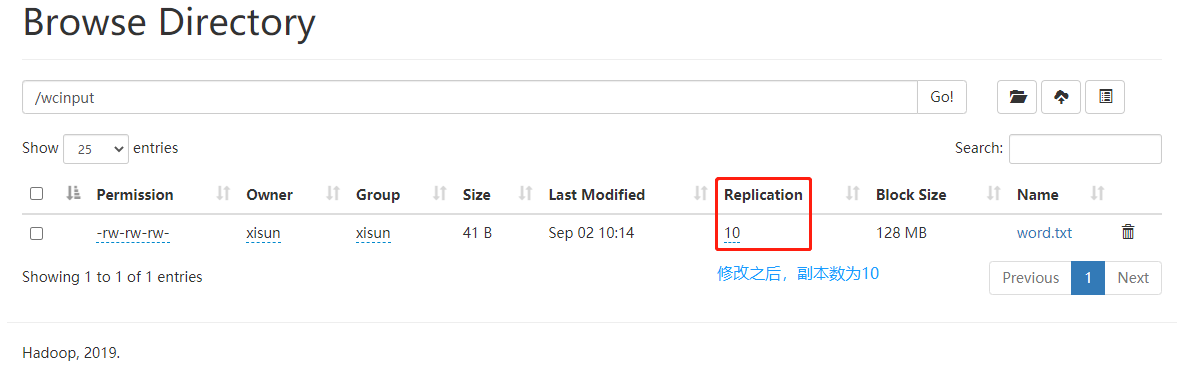
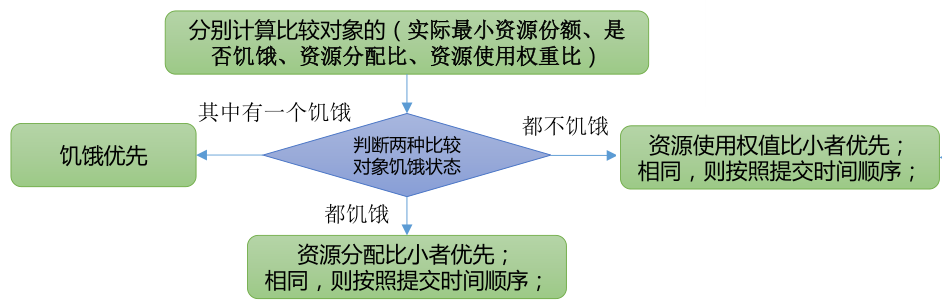
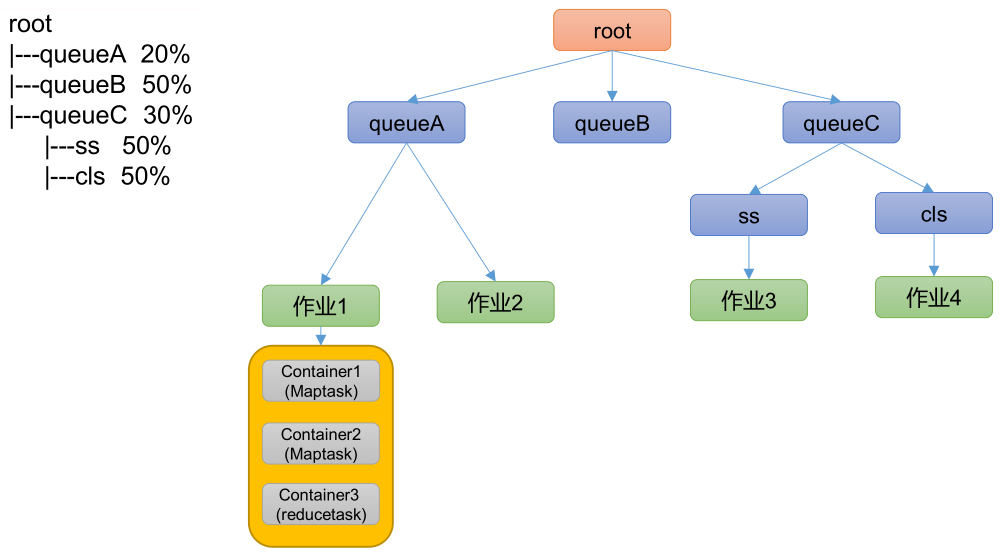
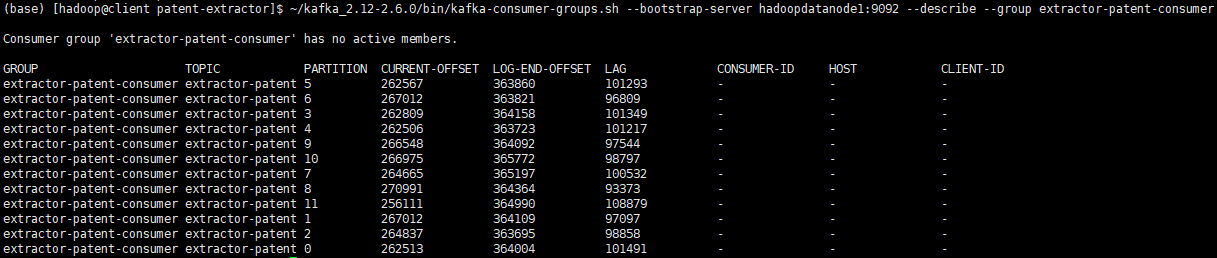
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
| [root@hadoop102 opt]# cephadm ls
[
{
"style": "cephadm:v1",
"name": "mon.hadoop102",
"fsid": "81b469b6-662d-11ec-b2eb-000c29c51d96",
"systemd_unit": "ceph-81b469b6-662d-11ec-b2eb-000c29c51d96@mon.hadoop102",
"enabled": true,
"state": "running",
"container_id": "db378568f82337811eff2c7c44ad1a713d955a5b04fcde47c18674671e735704",
"container_image_name": "quay.io/ceph/ceph:v15",
"container_image_id": "3437f7bed9688a799444b439e1947a6f00d1f9b1fc986e843aec7e3ac8acd12b",
"version": "15.2.15",
"started": "2021-12-27T09:11:27.486408Z",
"created": "2021-12-26T09:23:53.780886Z",
"deployed": "2021-12-26T09:23:52.866923Z",
"configured": "2021-12-26T09:30:45.494492Z"
},
{
"style": "cephadm:v1",
"name": "mgr.hadoop102.kwrjaw",
"fsid": "81b469b6-662d-11ec-b2eb-000c29c51d96",
"systemd_unit": "ceph-81b469b6-662d-11ec-b2eb-000c29c51d96@mgr.hadoop102.kwrjaw",
"enabled": true,
"state": "running",
"container_id": "32e7e6a303b2af413b90739fde7e1f3b60c26214a1a5fe8d34d36133f733ea61",
"container_image_name": "quay.io/ceph/ceph:v15",
"container_image_id": "3437f7bed9688a799444b439e1947a6f00d1f9b1fc986e843aec7e3ac8acd12b",
"version": "15.2.15",
"started": "2021-12-27T09:11:24.388823Z",
"created": "2021-12-26T09:23:57.956720Z",
"deployed": "2021-12-26T09:23:57.302746Z",
"configured": "2021-12-26T09:30:46.551456Z"
},
{
"style": "cephadm:v1",
"name": "alertmanager.hadoop102",
"fsid": "81b469b6-662d-11ec-b2eb-000c29c51d96",
"systemd_unit": "ceph-81b469b6-662d-11ec-b2eb-000c29c51d96@alertmanager.hadoop102",
"enabled": true,
"state": "running",
"container_id": "843d8e781d923fa302322c78e5251ab1fa4b7b3d5a5998906ee30e089cc2e506",
"container_image_name": "quay.io/prometheus/alertmanager:v0.20.0",
"container_image_id": "0881eb8f169f5556a292b4e2c01d683172b12830a62a9225a98a8e206bb734f0",
"version": "0.20.0",
"started": "2021-12-27T09:11:30.498509Z",
"created": "2021-12-26T09:25:51.990176Z",
"deployed": "2021-12-26T09:25:51.485197Z",
"configured": "2021-12-26T09:30:48.260398Z"
},
{
"style": "cephadm:v1",
"name": "crash.hadoop102",
"fsid": "81b469b6-662d-11ec-b2eb-000c29c51d96",
"systemd_unit": "ceph-81b469b6-662d-11ec-b2eb-000c29c51d96@crash.hadoop102",
"enabled": true,
"state": "running",
"container_id": "2d08d2614605c2a4350c56cf1733f85cd5916afc03a899ce65c600a437c36184",
"container_image_name": "quay.io/ceph/ceph:v15",
"container_image_id": "3437f7bed9688a799444b439e1947a6f00d1f9b1fc986e843aec7e3ac8acd12b",
"version": "15.2.15",
"started": "2021-12-27T09:11:28.253480Z",
"created": "2021-12-26T09:25:54.341083Z",
"deployed": "2021-12-26T09:25:53.839103Z",
"configured": "2021-12-26T09:25:54.341083Z"
},
{
"style": "cephadm:v1",
"name": "grafana.hadoop102",
"fsid": "81b469b6-662d-11ec-b2eb-000c29c51d96",
"systemd_unit": "ceph-81b469b6-662d-11ec-b2eb-000c29c51d96@grafana.hadoop102",
"enabled": true,
"state": "running",
"container_id": "cbb4a8a923e2f3205e02e9dd026d3fdcf1a07c55a3eda6b9de13408dadc0465a",
"container_image_name": "quay.io/ceph/ceph-grafana:6.7.4",
"container_image_id": "557c83e11646f123a27b5e4b62ac6c45e7bb8b2e90d6044034d0db5b7019415c",
"version": "6.7.4",
"started": "2021-12-27T09:11:27.676553Z",
"created": "2021-12-26T09:29:44.175925Z",
"deployed": "2021-12-26T09:29:42.555990Z",
"configured": "2021-12-26T09:30:51.194299Z"
},
{
"style": "cephadm:v1",
"name": "node-exporter.hadoop102",
"fsid": "81b469b6-662d-11ec-b2eb-000c29c51d96",
"systemd_unit": "ceph-81b469b6-662d-11ec-b2eb-000c29c51d96@node-exporter.hadoop102",
"enabled": true,
"state": "running",
"container_id": "ee29b873a834252d1d55c20c67ecfbff9a3b6acf8621063efd9070a79cb1cba5",
"container_image_name": "quay.io/prometheus/node-exporter:v0.18.1",
"container_image_id": "e5a616e4b9cf68dfcad7782b78e118be4310022e874d52da85c55923fb615f87",
"version": "0.18.1",
"started": "2021-12-27T09:11:21.758252Z",
"created": "2021-12-26T09:29:47.899777Z",
"deployed": "2021-12-26T09:29:47.307801Z",
"configured": "2021-12-26T09:29:47.899777Z"
},
{
"style": "cephadm:v1",
"name": "prometheus.hadoop102",
"fsid": "81b469b6-662d-11ec-b2eb-000c29c51d96",
"systemd_unit": "ceph-81b469b6-662d-11ec-b2eb-000c29c51d96@prometheus.hadoop102",
"enabled": true,
"state": "running",
"container_id": "f236295847bf07d2db2b3c79d3a209f5db369cf2a61ae7bb7d2ef7597982eb23",
"container_image_name": "quay.io/prometheus/prometheus:v2.18.1",
"container_image_id": "de242295e2257c37c8cadfd962369228f8f10b2d48a44259b65fef44ad4f6490",
"version": "2.18.1",
"started": "2021-12-27T09:11:25.545626Z",
"created": "2021-12-26T09:30:36.125856Z",
"deployed": "2021-12-26T09:30:35.546879Z",
"configured": "2021-12-26T09:30:36.125856Z"
}
]
|