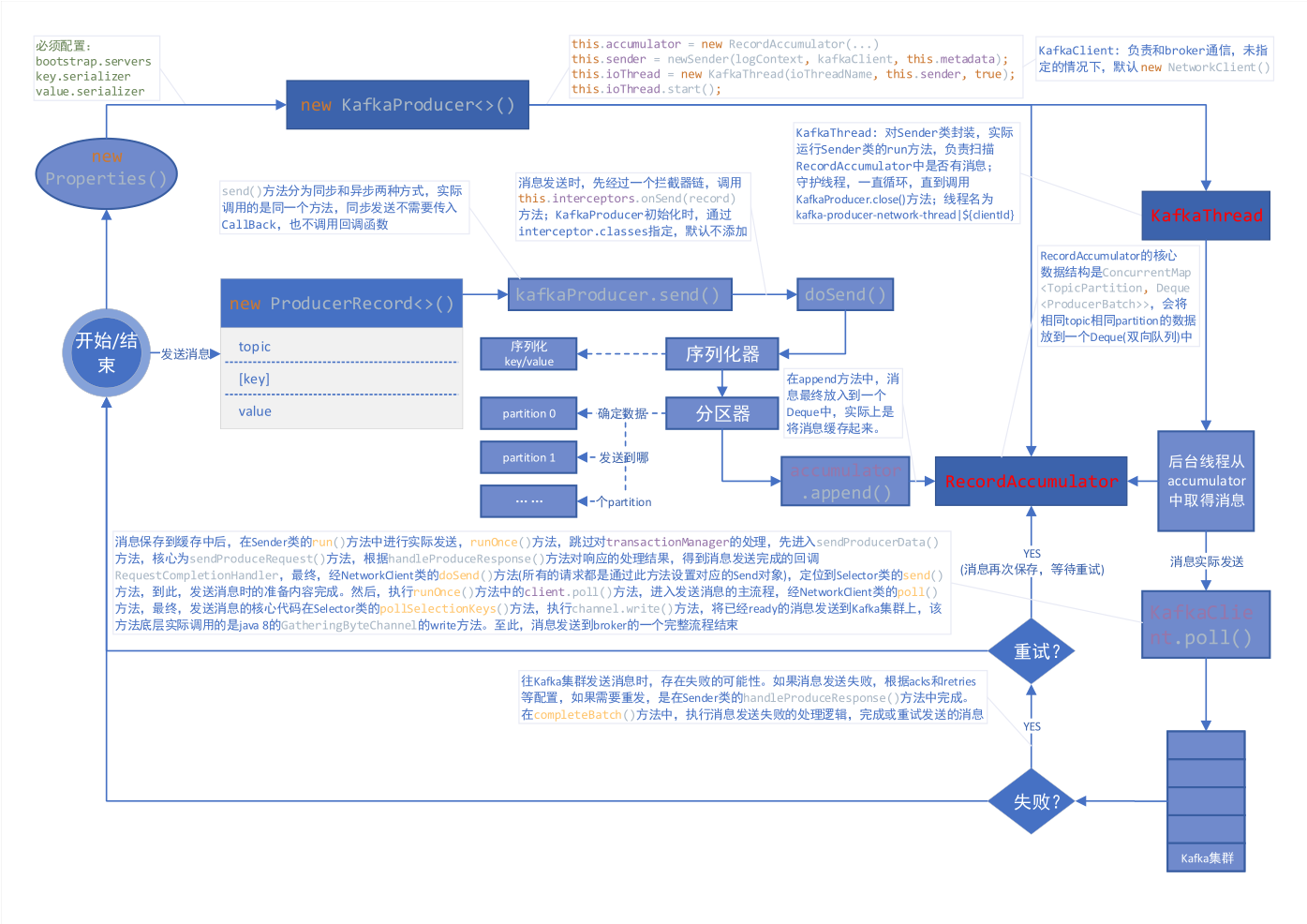
this.accumulator = new RecordAccumulator(logContext, config.getInt(ProducerConfig.BATCH_SIZE_CONFIG), this.compressionType, lingerMs(config), retryBackoffMs, deliveryTimeoutMs, metrics, PRODUCER_METRIC_GROUP_NAME, time, apiVersions, transactionManager, new BufferPool(this.totalMemorySize, config.getInt(ProducerConfig.BATCH_SIZE_CONFIG), metrics, time, PRODUCER_METRIC_GROUP_NAME));
public Future<RecordMetadata> send(ProducerRecord<K, V> record){ return send(record, null); }
异步 send:
1 2 3 4 5
public Future<RecordMetadata> send(ProducerRecord<K, V> record, Callback callback){ // intercept the record, which can be potentially modified; this method does not throw exceptions ProducerRecord<K, V> interceptedRecord = this.interceptors.onSend(record); return doSend(interceptedRecord, callback); }
可以看出,同步和异步实际上调用的是同一个方法,同步发送时,设置回调函数为 null。
消息发送之前,会先对 key 和 value 进行序列化:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
byte[] serializedKey; try { serializedKey = keySerializer.serialize(record.topic(), record.headers(), record.key()); } catch (ClassCastException cce) { thrownew SerializationException("Can't convert key of class " + record.key().getClass().getName() + " to class " + producerConfig.getClass(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG).getName() + " specified in key.serializer", cce); } byte[] serializedValue; try { serializedValue = valueSerializer.serialize(record.topic(), record.headers(), record.value()); } catch (ClassCastException cce) { thrownew SerializationException("Can't convert value of class " + record.value().getClass().getName() + " to class " + producerConfig.getClass(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG).getName() + " specified in value.serializer", cce); }
计算分区:
1
int partition = partition(record, serializedKey, serializedValue, cluster);
发送消息,实际上是将消息缓存起来,核心代码如下:
1 2
RecordAccumulator.RecordAppendResult result = accumulator.append(tp, timestamp, serializedKey, serializedValue, headers, interceptCallback, remainingWaitMs);
/** * The background thread that handles the sending of produce requests to the Kafka cluster. This thread makes metadata * requests to renew its view of the cluster and then sends produce requests to the appropriate nodes. */ publicclassSenderimplementsRunnable{ /** * The main run loop for the sender thread */ publicvoidrun(){ // main loop, runs until close is called while (running) { try { runOnce(); } catch (Exception e) { log.error("Uncaught error in kafka producer I/O thread: ", e); } } // okay we stopped accepting requests but there may still be // requests in the transaction manager, accumulator or waiting for acknowledgment, // wait until these are completed. while (!forceClose && ((this.accumulator.hasUndrained() || this.client.inFlightRequestCount() > 0) || hasPendingTransactionalRequests())) { try { runOnce(); } catch (Exception e) { log.error("Uncaught error in kafka producer I/O thread: ", e); } }
// Abort the transaction if any commit or abort didn't go through the transaction manager's queue while (!forceClose && transactionManager != null && transactionManager.hasOngoingTransaction()) { if (!transactionManager.isCompleting()) { log.info("Aborting incomplete transaction due to shutdown"); transactionManager.beginAbort(); } try { runOnce(); } catch (Exception e) { log.error("Uncaught error in kafka producer I/O thread: ", e); } }
if (forceClose) { // We need to fail all the incomplete transactional requests and batches and wake up the threads waiting on // the futures. if (transactionManager != null) { log.debug("Aborting incomplete transactional requests due to forced shutdown"); transactionManager.close(); } log.debug("Aborting incomplete batches due to forced shutdown"); this.accumulator.abortIncompleteBatches(); } } }
for (ProducerBatch batch : batches) { TopicPartition tp = batch.topicPartition; // 将ProducerBatch中MemoryRecordsBuilder转换为MemoryRecords(发送的数据就在这里面) MemoryRecords records = batch.records();
// down convert if necessary to the minimum magic used. In general, there can be a delay between the time // that the producer starts building the batch and the time that we send the request, and we may have // chosen the message format based on out-dated metadata. In the worst case, we optimistically chose to use // the new message format, but found that the broker didn't support it, so we need to down-convert on the // client before sending. This is intended to handle edge cases around cluster upgrades where brokers may // not all support the same message format version. For example, if a partition migrates from a broker // which is supporting the new magic version to one which doesn't, then we will need to convert. if (!records.hasMatchingMagic(minUsedMagic)) records = batch.records().downConvert(minUsedMagic, 0, time).records(); produceRecordsByPartition.put(tp, records); recordsByPartition.put(tp, batch); }
/* if channel is ready write to any sockets that have space in their buffer and for which we have data */ if (channel.ready() && key.isWritable() && !channel.maybeBeginClientReauthentication( () -> channelStartTimeNanos != 0 ? channelStartTimeNanos : currentTimeNanos)) { Send send; try { // 底层实际调用的是java8 GatheringByteChannel的write方法 send = channel.write(); } catch (Exception e) { sendFailed = true; throw e; } if (send != null) { this.completedSends.add(send); this.sensors.recordBytesSent(channel.id(), send.size()); } }
/** * Complete or retry the given batch of records. * * @param batch The record batch * @param response The produce response * @param correlationId The correlation id for the request * @param now The current POSIX timestamp in milliseconds */ privatevoidcompleteBatch(ProducerBatch batch, ProduceResponse.PartitionResponse response, long correlationId, long now, long throttleUntilTimeMs){ Errors error = response.error;
if (error == Errors.MESSAGE_TOO_LARGE && batch.recordCount > 1 && !batch.isDone() && (batch.magic() >= RecordBatch.MAGIC_VALUE_V2 || batch.isCompressed())) { // If the batch is too large, we split the batch and send the split batches again. We do not decrement // the retry attempts in this case.(如果发送的消息太大,需要重新进行分割发送) this.accumulator.splitAndReenqueue(batch); maybeRemoveAndDeallocateBatch(batch); this.sensors.recordBatchSplit(); } elseif (error != Errors.NONE) { // 发生了错误,如果此时可以retry(retry次数未达到限制以及产生的异常是RetriableException) if (canRetry(batch, response, now)) { if (transactionManager == null) { // 把需要重试的消息放入队列中,等待重试,实际就是调用deque.addFirst(batch) reenqueueBatch(batch, now); } ... } ... } }
以上,就是 KafkaProducer 发送消息的流程。
补充:分区算法
在发送消息前,调用的计算分区方法如下:
1 2 3 4 5 6 7 8 9 10 11 12
/** * computes partition for given record. * if the record has partition returns the value otherwise * calls configured partitioner class to compute the partition. */ privateintpartition(ProducerRecord<K, V> record, byte[] serializedKey, byte[] serializedValue, Cluster cluster){ Integer partition = record.partition(); return partition != null ? partition : partitioner.partition( record.topic(), record.key(), serializedKey, record.value(), serializedValue, cluster); }
/** * The default partitioning strategy: * <ul> * <li>If a partition is specified in the record, use it * <li>If no partition is specified but a key is present choose a partition based on a hash of the key * <li>If no partition or key is present choose a partition in a round-robin fashion */ publicclassDefaultPartitionerimplementsPartitioner{
privatefinal ConcurrentMap<String, AtomicInteger> topicCounterMap = new ConcurrentHashMap<>();
publicvoidconfigure(Map<String, ?> configs){}
/** * Compute the partition for the given record. * * @param topic The topic name * @param key The key to partition on (or null if no key) * @param keyBytes serialized key to partition on (or null if no key) * @param value The value to partition on or null * @param valueBytes serialized value to partition on or null * @param cluster The current cluster metadata */ publicintpartition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster){ List<PartitionInfo> partitions = cluster.partitionsForTopic(topic); int numPartitions = partitions.size(); if (keyBytes == null) { // 如果key为null,则使用Round Robin算法 int nextValue = nextValue(topic); List<PartitionInfo> availablePartitions = cluster.availablePartitionsForTopic(topic); if (availablePartitions.size() > 0) { int part = Utils.toPositive(nextValue) % availablePartitions.size(); return availablePartitions.get(part).partition(); } else { // no partitions are available, give a non-available partition return Utils.toPositive(nextValue) % numPartitions; } } else { // hash the keyBytes to choose a partition(根据key进行散列,使用murmur2算法) return Utils.toPositive(Utils.murmur2(keyBytes)) % numPartitions; } }