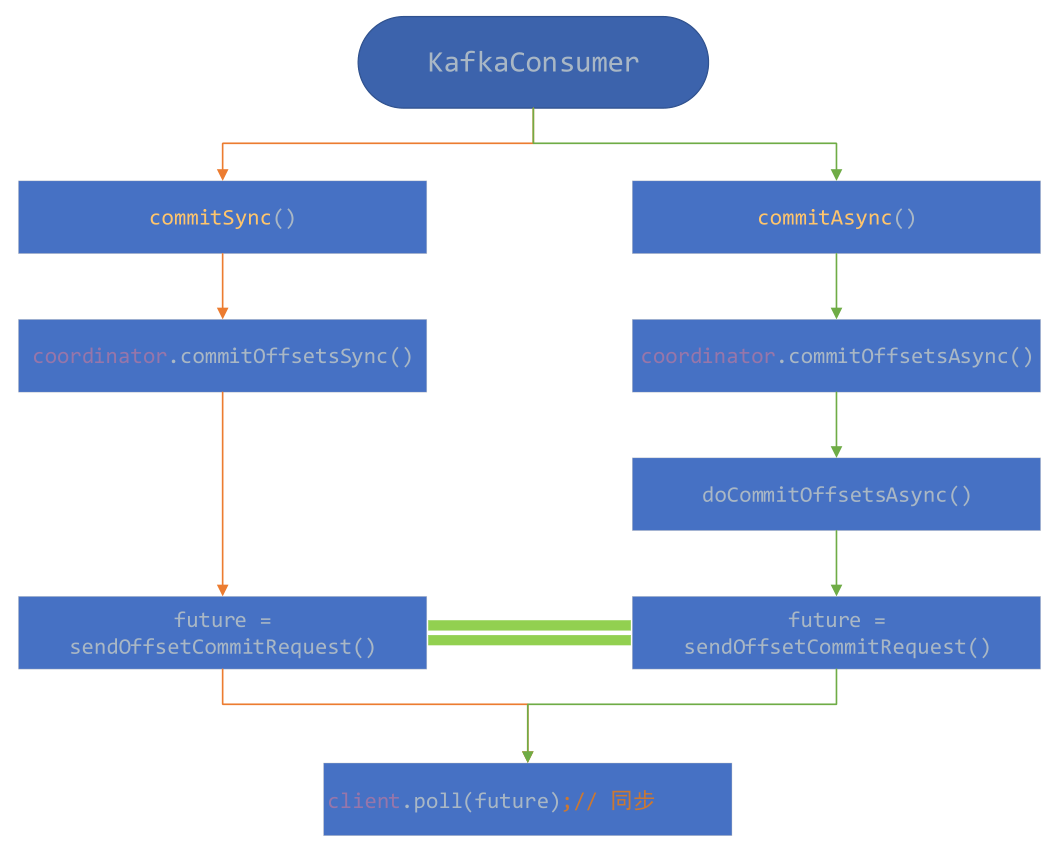
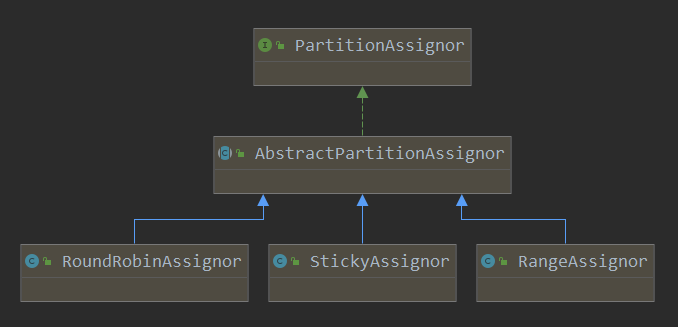
/** * Perform the group assignment given the partition counts and member subscriptions * @param partitionsPerTopic The number of partitions for each subscribed topic. Topics not in metadata will be excluded * from this map. * @param subscriptions Map from the memberId to their respective topic subscription * @return Map from each member to the list of partitions assigned to them. */ // 根据partitionsPerTopic和subscriptions进行分配,具体的实现会在子类中实现(不同的子类,其实现方法不相同) publicabstract Map<String, List<TopicPartition>> assign(Map<String, Integer> partitionsPerTopic, Map<String, Subscription> subscriptions);
// a mapping of all topic partitions to all consumers that can be assigned to them final Map<TopicPartition, List<String>> partition2AllPotentialConsumers = new HashMap<>(); // a mapping of all consumers to all potential topic partitions that can be assigned to them final Map<String, List<TopicPartition>> consumer2AllPotentialPartitions = new HashMap<>();
// initialize partition2AllPotentialConsumers and consumer2AllPotentialPartitions in the following two for loops for (Entry<String, Integer> entry: partitionsPerTopic.entrySet()) { for (int i = 0; i < entry.getValue(); ++i) partition2AllPotentialConsumers.put(new TopicPartition(entry.getKey(), i), new ArrayList<>()); }
for (Entry<String, Subscription> entry: subscriptions.entrySet()) { String consumer = entry.getKey(); consumer2AllPotentialPartitions.put(consumer, new ArrayList<>()); entry.getValue().topics().stream().filter(topic -> partitionsPerTopic.get(topic) != null).forEach(topic -> { for (int i = 0; i < partitionsPerTopic.get(topic); ++i) { TopicPartition topicPartition = new TopicPartition(topic, i); consumer2AllPotentialPartitions.get(consumer).add(topicPartition); partition2AllPotentialConsumers.get(topicPartition).add(consumer); } });
// add this consumer to currentAssignment (with an empty topic partition assignment) if it does not already exist if (!currentAssignment.containsKey(consumer)) currentAssignment.put(consumer, new ArrayList<>()); }
// a mapping of partition to current consumer Map<TopicPartition, String> currentPartitionConsumer = new HashMap<>(); for (Map.Entry<String, List<TopicPartition>> entry: currentAssignment.entrySet()) for (TopicPartition topicPartition: entry.getValue()) currentPartitionConsumer.put(topicPartition, entry.getKey());
// all partitions that need to be assigned (initially set to all partitions but adjusted in the following loop) List<TopicPartition> unassignedPartitions = new ArrayList<>(sortedPartitions); for (Iterator<Map.Entry<String, List<TopicPartition>>> it = currentAssignment.entrySet().iterator(); it.hasNext();) { Map.Entry<String, List<TopicPartition>> entry = it.next(); if (!subscriptions.containsKey(entry.getKey())) { // if a consumer that existed before (and had some partition assignments) is now removed, remove it from currentAssignment for (TopicPartition topicPartition: entry.getValue()) currentPartitionConsumer.remove(topicPartition); it.remove(); } else { // otherwise (the consumer still exists) for (Iterator<TopicPartition> partitionIter = entry.getValue().iterator(); partitionIter.hasNext();) { TopicPartition partition = partitionIter.next(); if (!partition2AllPotentialConsumers.containsKey(partition)) { // if this topic partition of this consumer no longer exists remove it from currentAssignment of the consumer partitionIter.remove(); currentPartitionConsumer.remove(partition); } elseif (!subscriptions.get(entry.getKey()).topics().contains(partition.topic())) { // if this partition cannot remain assigned to its current consumer because the consumer // is no longer subscribed to its topic remove it from currentAssignment of the consumer partitionIter.remove(); } else // otherwise, remove the topic partition from those that need to be assigned only if // its current consumer is still subscribed to its topic (because it is already assigned // and we would want to preserve that assignment as much as possible) unassignedPartitions.remove(partition); } } } // at this point we have preserved all valid topic partition to consumer assignments and removed // all invalid topic partitions and invalid consumers. Now we need to assign unassignedPartitions // to consumers so that the topic partition assignments are as balanced as possible.
// an ascending sorted set of consumers based on how many topic partitions are already assigned to them TreeSet<String> sortedCurrentSubscriptions = new TreeSet<>(new SubscriptionComparator(currentAssignment)); sortedCurrentSubscriptions.addAll(currentAssignment.keySet());