计算机基础知识
Windows 的命令行
用户界面分成两种:TUI(文本交互界面)和 GUI(图形化交互界面)。
命令行就是文本交互界面,通过命令行可以使用一个一个的指令来操作计算机。
任何计算机的操作系统中都包含有命令行(Windows、Linux、MacOS),命令行有多个不同的名字:命令行、命令行窗口、DOS 窗口、命令提示符、CMD 窗口、Shell、终端、Terminal。
命令行的进入方式:
win 键 + R,出现运行窗口,输入cmd,然后回车。命令行的结构
1
2
3
4Microsoft Windows [版本 10.0.19042.1165]
(c) Microsoft Corporation。保留所有权利。
C:\Users\Xisun>- 上面两行为版本及版权声明(一般没有什么用)
- 最下面一行为命令提示符
- `C`:当前所在的磁盘根目录,通过 `x:` 来切换盘符(x 表示你的盘符)。 - `\Users\Xisun`:当前所在磁盘的路径,通过 `cd` 来切换目录。 - `>`:命令提示符,在符号后边可以直接输入指令。
常用的 DOS 命令
- 语法:
命令 [参数] [选项] dir:查看当前目录下的所有文件(夹)cd:进入到指定的目录.:表示当前目录。..:表示上一级目录。
md:创建一个目录。rd:删除一个目录。del:删除一个文件。cls:清除屏幕。- 小技巧:方向键上下,查看命令的历史记录;tab 键自动补全命令。
- 语法:
环境变量
- 环境变量指的就是操作系统当中的一些变量。可以通过修改环境变量,来对计算机进行配置(主要是来配置一些路径的)。
- 查看环境变量
- 右键计算机(此电脑)—> 选择属性 —> 系统界面左侧选择高级系统设置 —> 选择环境变量。
- 环境变量界面分成了两个部分,上边是用户环境变量,下边是系统环境变量。
- 用户环境变量只对当前用户有效,系统环境变量对所有用户有效。
- 添加环境变量
- 通过新建按钮添加环境变量。
- 一个环境变量可以由多个值,值与值之间使用
;隔开。
- 修改环境变量
- 通过编辑按钮来修改环境变量。
- 删除环境变量
- 通过删除按钮来删除环境变量。
path 环境变量
- path 环境变量中保存的是一个一个的路径。当我们在命令行中输入一个命令(或访问一个文件时),系统会首先在当前目录下寻找,如果找到了则直接执行或打开;如果没有找到,则会依次去 path 环境变量的路径中去寻找,直到找到为止;如果 path 环境变量中的路径都没有找到,则报错:
'xxx' 不是内部或外部命令,也不是可运行的程序或批处理文件。 - 将一些经常需要访问到的文件或程序的路径,添加到 path 环境变量中,这样就可以在任意的位置访问到这些文件或程序。
- 注意事项:
- 如果环境变量中没有 path,可以手动添加。
- path 环境变量不区分大小写:PATH、Path 或 path。
- 修改完环境变量必须重新启动命令行窗口。
- 多个路径之间使用
;隔开。
进制
- 十进制
- 十进制是最常用的进制。
- 十进制算法:满十进一。
- 十进制当中一共有 10 个数字:0,1,2,3,4,5,6,7,8,9。
- 十进制如何计数:0,1,2,3,4,5,6,7,8,9;10,11,12,。。。,19;20,。。。,29;30,…
- 个位表示有几个 1,十位表示有几个 10,百位表示有几个 100,千位表示有几个 1000,以此类推。如:5421。
- 二进制
- 二进制是计算机底层使用的进制。
- 所有的数据在计算机底层都是以二进制的形式保存的,计算机只认二进制。
- 可以将内存想象为一个一个的小格子,小格子中可以存储一个 0 或一个 1。
- 内存中的每一个小格子,我们称为 1 bit(1 位)。
- bit 是计算机中的最小的单位。
- byte 是我们可操作的最小的单位。
- 8 bit = 1 byte(字节)
- 1024 byte = 1 kb(千字节)
- 1024 kb = 1 mb(兆字节)
- 1024 mb = 1 gb(吉字节)
- 1024 gb = 1 tb(太字节)
- 二进制算法:满二进一。
- 二进制中一共有 2 个数字:0,1。
- 二进制如何计数:0,1;10,11;100,101,110,111;1000,…
- 第一位表示有几个 1,第二位表示有几个 2,第三位表示有几个 4,第四位表示有几个 8,依次类推。如:1011。
- 二进制是计算机底层使用的进制。
- 八进制
- 一般不用。
- 八进制算法:满八进一。
- 八进制中一共有 8 个数字:0,1,2,3,4,5,6,7。
- 八进制如何计数:0,1,2,3,4,5,6,7;10,11,…,17;20,21,…,27;…
- 十六进制
- 在查看二进制数据时,一般会以十六进制的形式显示。
- 十六进制算法:满十六进一。
- 十六进制中一共有 16 个数字:0,1,2,3,4,5,6,7,8,9,a,b,c,d,e,f 。
- 由于十六进制是满 16 才进位,所以十六进制中引入了 a,b,c,d,e,f 来表示 10,11,12,13,14,15。
- 十六进制如何计数:0,1,2,3,4,5,6,7,8,9,a,b,c,d,e,f ;10,11,12 ,…,1a,1b,1c,1d,1e,1f,20,21,22,…,2a,2b,2c,2d,2e,2f;30,…
文本文件和字符集
文本分成两种,一种叫做纯文本,还有一种叫做富文本。
纯文本中只能保存单一的文本内容,无法保存内容无关的东西(如字体、颜色、图片等)。常见的纯文本如记事本。
富文本中可以保存文本以外的内容。常见的富文本如 word 文档。
在开发时,编写程序使用的全都是纯文本!
纯文本在计算机底层也会转换为二进制保存:
- 将字符转换为二进制码的过程,称为编码。
- 将二进制码转换为字符的过程,称为解码。
- 编码和解码时所采用的规则,称为字符集。
常见的字符集:
- ASCII
- 美国人编码,使用 7 位来对美国常用的字符进行编码。
- 包含 128 个字符。
- ISO-8859-1
- 欧洲的编码,使用 8 位来对欧洲常用的字符进行编码。
- 包含 256 个字符。
- GB2312,GBK
- 国标码,中国的编码。
- Unicode
- 万国码,包含世界上所有的语言和符号,编写程序时一般都会使用 Unicode 编码。
- Unicode 编码有多种实现,如 UTF-8,UTF-16,UTF-32,最常用的就是 UTF-8。
- ASCII
乱码:编写程序时,如果发现程序代码出现乱码的情况,就要马上去检查字符集是否正确。
计算机语言
- 计算机语言就是用来控制计算机的编程语言。
- 计算机语言发展经历了三个阶段:
- 机器语言
- 机器语言通过二进制编码来编写程序。
- 执行效率好,但编写起来太麻烦。
- 符号语言/汇编语言
- 使用符号来代替机器码。
- 编写程序时,不需要使用二进制,而是直接编写符号。
- 编写完成后,需要将符号转换为机器码,然后再由计算机执行。
- 将符号转换为机器码的过程,称为汇编。
- 将机器码转换为符号的过程,称为反汇编。
- 汇编语言一般只适用于某些硬件,兼容性比较差。
- 高级语言
- 高级语言的语法基本和现在英语语法类似,并且和硬件的关系没有那么紧密了。
- 也就是说我们通过高级语言开发的程序,可以在不同的硬件系统中执行。
- 并且高级语言学习起来也更加的容易,现在我们知道的语言基本都是高级语言。比如:C、C++、C#、Java、JavaScript、Python等。
- 机器语言
编译型语言和解释型语言
计算机只能识别二进制编码(机器码),所以任何的语言在交由计算机执行时必须要先转换为机器码,也就是像
print('hello')必需要转换为类似1010101这样的机器码。根据转换时机的不同,语言分成了两大类:
编译型语言
- 会在代码执行前将代码编译为机器码,然后将机器码交由计算机执行。最典型的就是 C 语言。
- 过程:a(源码)—> 编译 —> b(编译后的机器码)。
- 特点:
- 执行速度特别快。
- 跨平台性比较差。
解释型语言
不会在执行前对代码进行编译,而是在执行的同时一边执行一边编译。比如 Python,JS,Java 等。
过程:a(源码)—> 解释器 —> 解释执行。
特点:
- 执行速度比较慢。
- 跨平台性比较好 。
Python 简介
- 现在,全世界差不多有 600 多种编程语言,但流行的编程语言也就那么 20 来种。
- 总的来说,每种编程语言各有千秋。C 语言是可以用来编写操作系统的贴近硬件的语言,所以,C 语言适合开发那些追求运行速度、充分发挥硬件性能的程序。而 Python 是用来编写应用程序的高级编程语言。
- Python 提供了非常完善的基础代码库,覆盖了网络、文件、GUI、数据库、文本等大量内容,被形象地称作“内置电池(batteries included)”。用 Python 开发,许多功能不必从零编写,直接使用现成的即可。
- 除了内置的库外,Python 还有大量的第三方库,也就是别人开发的,供你直接使用的东西。当然,如果你开发的代码通过很好的封装,也可以作为第三方库给别人使用。
- Python 的定位是“优雅”、“明确”、“简单”。Python 的哲学就是简单优雅,尽量写容易看明白的代码,尽量写少的代码。
- Python 适合开发的应用类型:
- 首选是网络应用,包括网站、后台服务等等。
- 其次是许多日常需要的小工具,包括系统管理员需要的脚本任务等等。
- 另外就是把其他语言开发的程序再包装起来,方便使用。
- Python 的缺点:
- 第一个缺点就是运行速度慢,和 C 程序相比非常慢,因为 Python 是解释型语言,编写的代码在执行时会一行一行地翻译成 CPU 能理解的机器码,这个翻译过程非常耗时,所以很慢。而 C 程序是运行前直接编译成 CPU 能执行的机器码,所以非常快。
- 第二个缺点就是代码不能加密。如果要发布编写的 Python 程序,实际上就是发布源代码,这一点跟 C 语言不同,C 语言不用发布源代码,只需要把编译后的机器码(也就是在 Windows 上常见的 xxx.exe 文件)发布出去。要从机器码反推出 C 代码是不可能的,所以,凡是编译型的语言,都没有这个问题,而解释型的语言,则必须把源码发布出去。
Python 安装
Python 是跨平台的,它可以运行在 Windows、Mac 和各种 Linux/Unix 系统上。在 Windows 上写 Python 程序,放到 Linux 上也是能够运行的。
要开始学习 Python 编程,首先就得把 Python 安装到你的电脑里。安装后,你会得到 Python 解释器(就是负责运行 Python 程序的),一个命令行交互环境,还有一个简单的集成开发环境。
目前,Python 有两个版本,一个是 2.x 版,一个是 3.x 版,这两个版本是不兼容的。由于 3.x 版越来越普及,此处选择安装 Windows 系统的 3.8 版本。
官方安装包安装
Python 官网:https://www.python.org/
Python 下载:
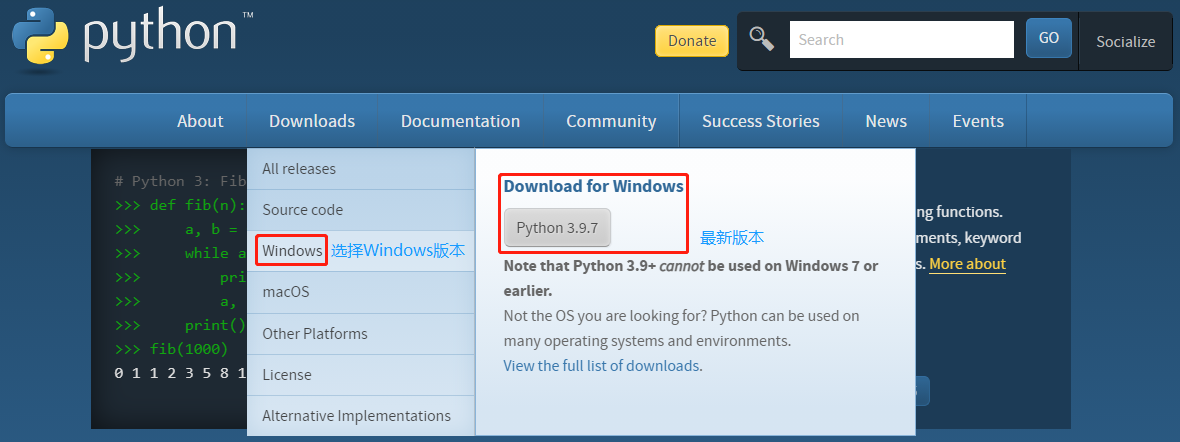
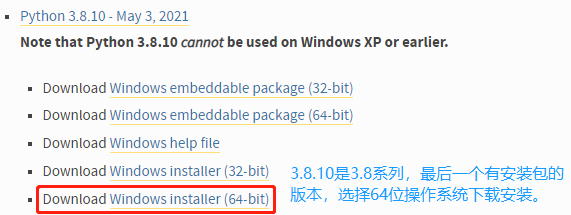
Python 安装:
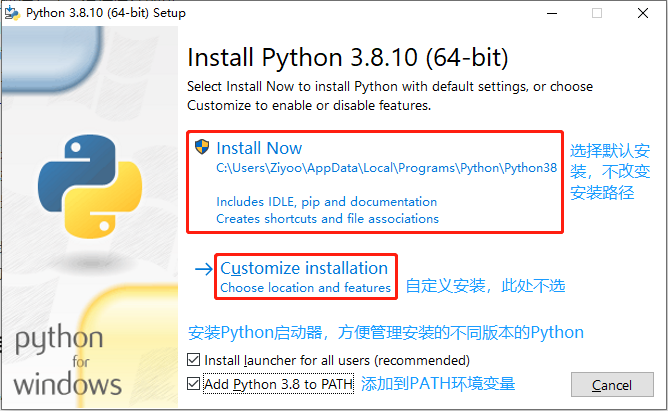
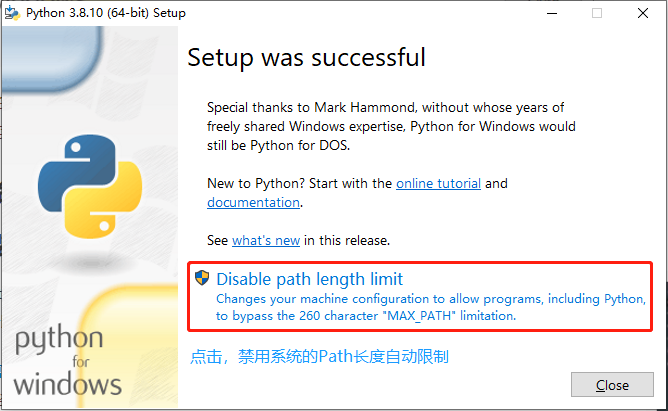
验证 Python 是否安装完成:
1
2
3
4
5
6
7
8
9
10Windows PowerShell
版权所有 (C) Microsoft Corporation。保留所有权利。
尝试新的跨平台 PowerShell https://aka.ms/pscore6
PS C:\Users\Xisun> python
Python 3.8.3 (default, May 19 2020, 06:50:17) [MSC v.1916 64 bit (AMD64)] :: Anaconda, Inc. on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> exit()
PS C:\Users\Xisun>- 提示符
>>>表示已经处于 Python 的交互模式中,可以输入任何 Python 代码,输入完的指令将会被 Python 的解释器立即执行。 - 输入
exit()并回车,可以退出 Python 交互模式(直接关掉命令行窗口也可以)。
- 提示符
安装 Python 的同时,会自动安装一个 Python 的开发工具 IDLE,通过 IDLE 也可以进入到交互模式。IDLE 中可以通过 tab 键来查看语句的提示,并且可以将代码保存。
交互模式下只能输入一行代码,执行一行,所以不适用于我们日常的开发,仅可以用来做一些日常的简单的测试!
我们一般会将 Python 代码编写到一个
.py文件中,然后通过 python 指令来执行文件中的代码。
Miniconda 安装
Miniconda 是一款小巧的 Python 环境管理工具,其安装程序中包含 conda 软件包管理器和 Python。一旦安装了 Miniconda,就可以使用 conda 命令安装任何其他软件工具包并创建环境等。
Windows 环境
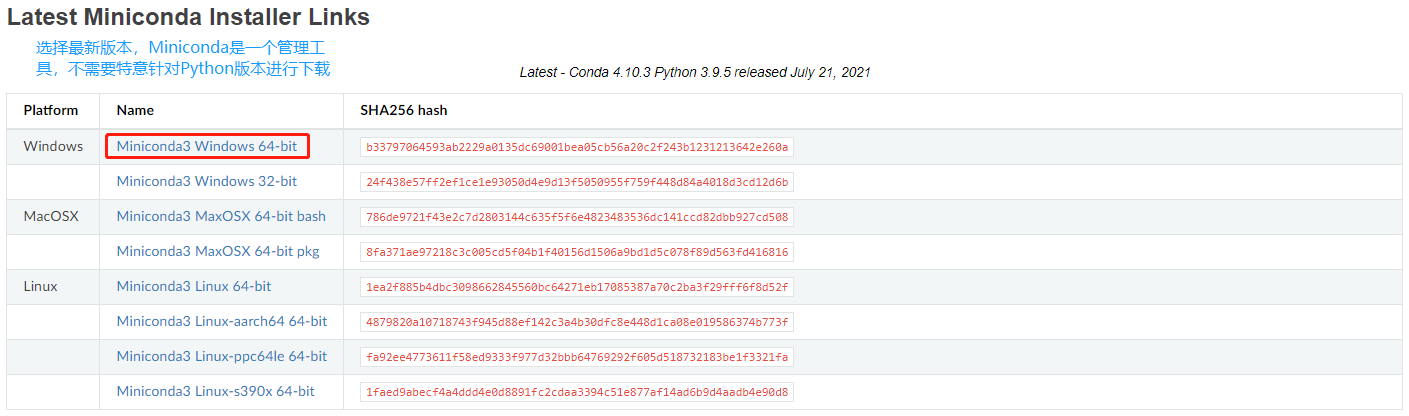
官网下载 Miniconda:
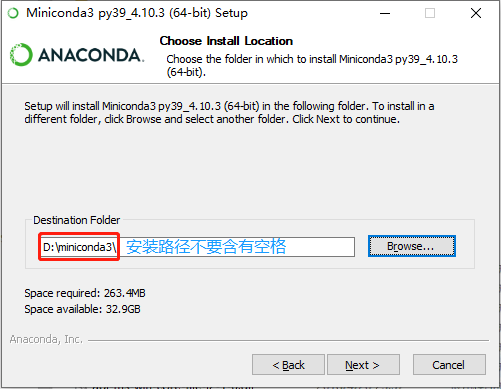
安装 Minicoda:
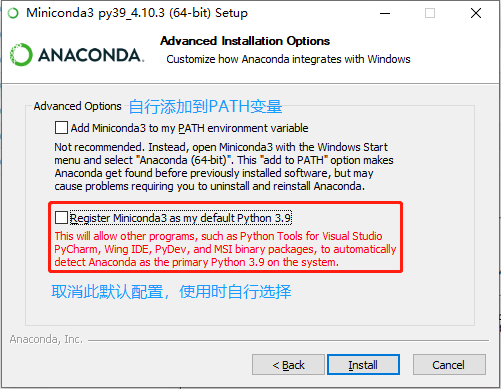
添加系统环境变量:
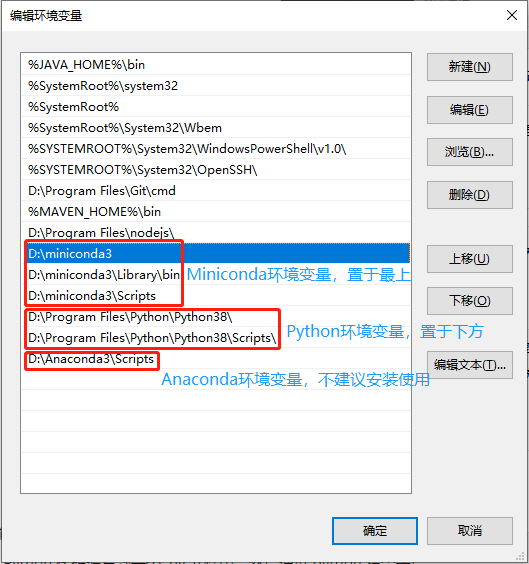
Windows PowerShell 中创建 Python 3.8 环境:
打开 Windows PowerShell:
1
2
3
4
5
6
7Windows PowerShell
版权所有 (C) Microsoft Corporation。保留所有权利。
尝试新的跨平台 PowerShell https://aka.ms/pscore6
加载个人及系统配置文件用了 907 毫秒。
(base) PS C:\Users\XiSun>查看所有的环境:
1
2
3
4(base) PS C:\Users\XiSun>conda env list
# conda environments:
#
base * D:\Program\Miniconda3创建一个新环境:
1
PS C:\Users\XiSun>conda create -n py38 python=3.8
建议针对不同的 Python 版本,创建不同的环境,
-n参数后是环境的名字,可以自取。Miniconda 自身的 Python 环境,不建议直接使用,避免污染。
新环境位于 Miniconda 安装目录下,如
D:\miniconda3\envs\py38。激活新创建的环境:
1
PS C:\Users\XiSun> conda activate py38
安装模块,可以多个一起安装:
1
2PS C:\Users\XiSun> conda init
PS C:\Users\XiSun> conda install numpy scipy pandas jupyter -y-y参数表示安装过程中询问是否继续操作时,默认输入y。使用 jupyter,首先创建一个目录,用于存放文件,如
D:\notebook:1
PS C:\Users\XiSun> jupyter notebook --notebook-dir D:\notebook\

jupyter 的部分操作:
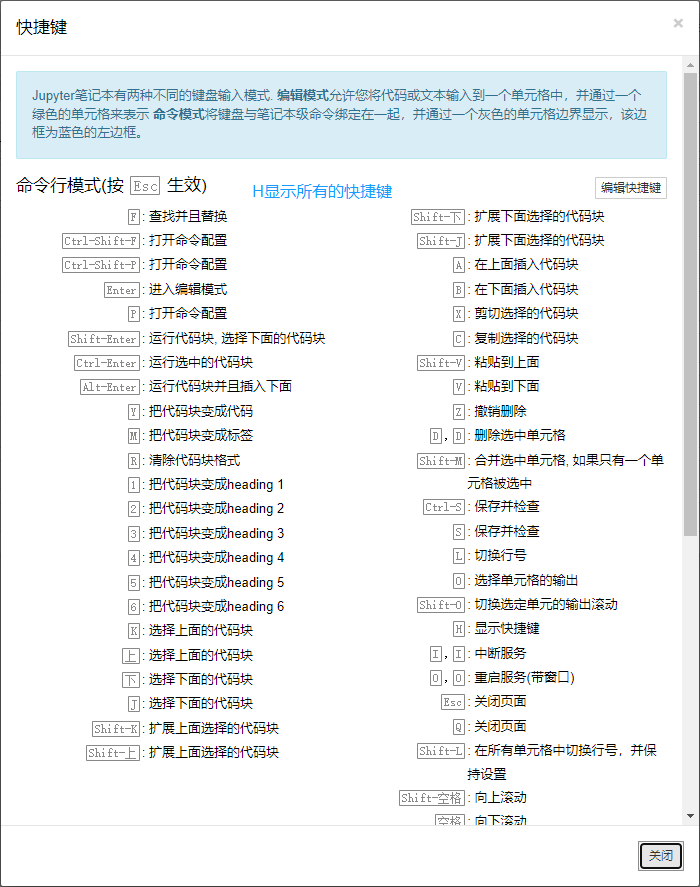
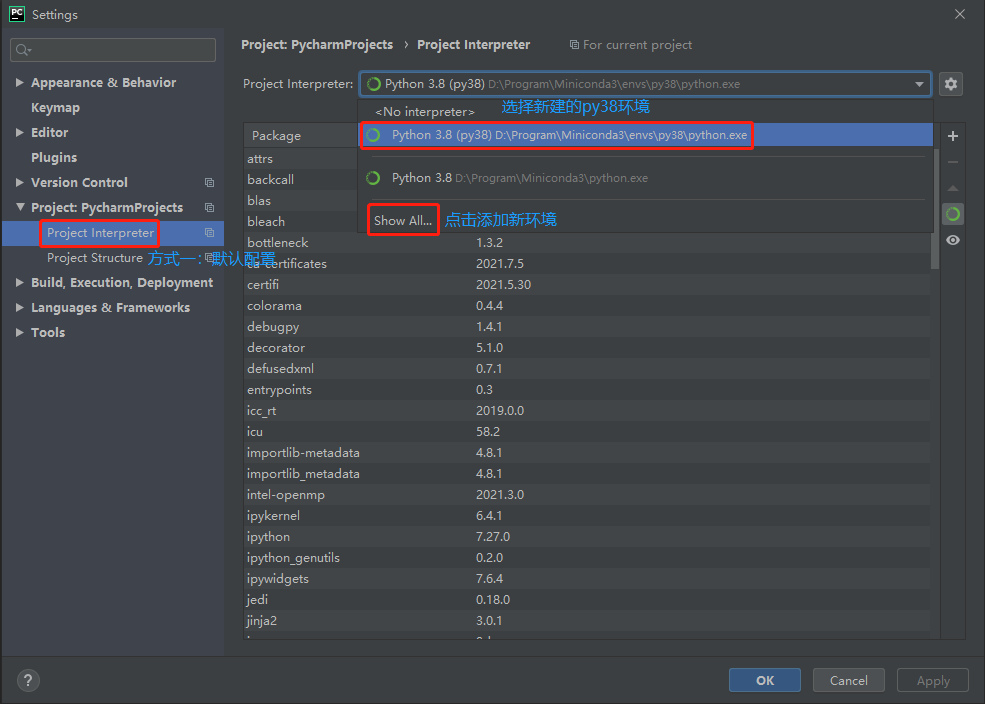
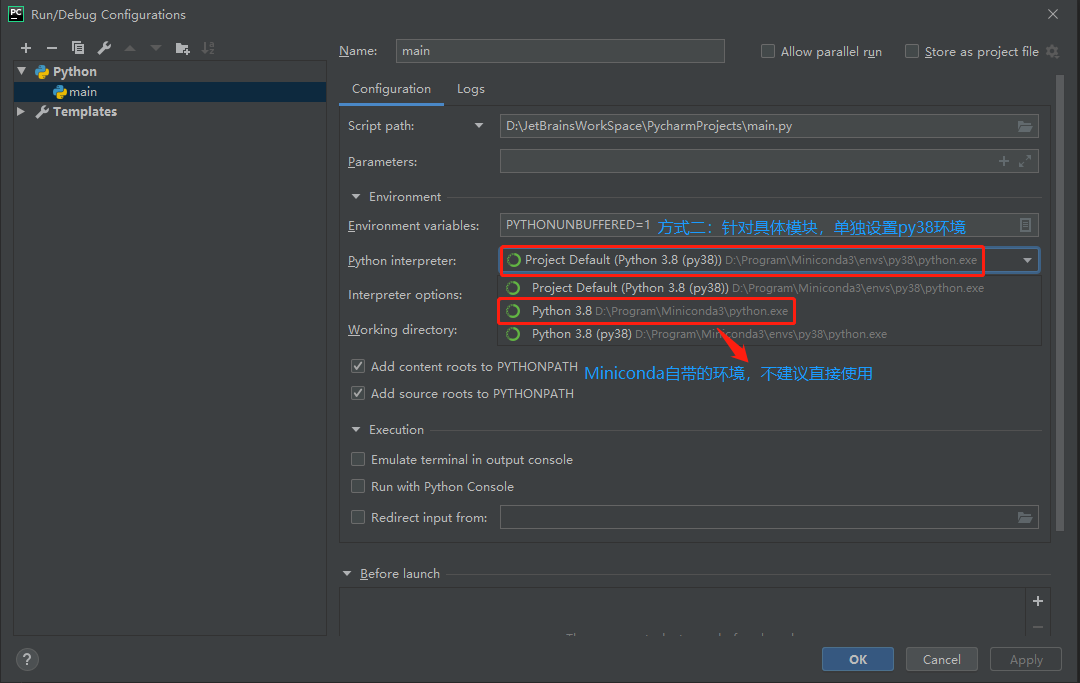
Pycharm 引用创建的 py38 环境:
Linux 环境
某些时候,可能会存在一些依赖包不支持 Windows 环境下载安装,这时候就需要在 Linux 环境下载安装使用。
WSL 中创建 Python 3.8 环境:
以管理员身份打开 Windows PowerShell:
1
2
3
4
5
6
7Windows PowerShell
版权所有 (C) Microsoft Corporation。保留所有权利。
尝试新的跨平台 PowerShell https://aka.ms/pscore6
加载个人及系统配置文件用了 869 毫秒。
(base) PS C:\XiSun\Ziyoo>开启 WSL:
1
2(base) PS C:\Users\XiSun> wsl
(base) xisun@DESKTOP-OM8IACS:/mnt/c/Users/XiSun$安装 Miniconda:
1
2
3
4
5
6
7(base) xisun@DESKTOP-OM8IACS:/mnt/c/Users/XiSun$ cd /mnt/d/Program\ Files/
(base) xisun@DESKTOP-OM8IACS:/mnt/d/Program Files$ ll
total 380636
drwxrwxrwx 1 xisun xisun 4096 Jan 25 10:29 ./
drwxrwxrwx 1 xisun xisun 4096 Jan 19 16:16 ../
-rwxrwxrwx 1 xisun xisun 85055499 Jun 10 2020 Miniconda3-latest-Linux-x86_64.sh*
(base) xisun@DESKTOP-OM8IACS:/mnt/d/Program Files$ sh Miniconda3-latest-Linux-x86_64.sh- Miniconda3-latest-Linux-x86_64.sh 是 Miniconda 安装程序。
创建一个新环境:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140(base) xisun@DESKTOP-OM8IACS:/mnt/c/Users/Ziyoo$ cd
(base) xisun@DESKTOP-OM8IACS:~$ ll
total 108
drwxr-xr-x 9 xisun xisun 4096 Jan 25 10:32 ./
drwxr-xr-x 3 root root 4096 Apr 26 2021 ../
-rw------- 1 xisun xisun 19888 Jan 25 10:33 .bash_history
-rw-r--r-- 1 xisun xisun 220 Apr 26 2021 .bash_logout
-rw-r--r-- 1 xisun xisun 4250 Jan 25 10:32 .bashrc
drwxr-xr-x 2 xisun xisun 4096 Jan 25 10:32 .conda/
drwxr-xr-x 8 xisun xisun 4096 Jun 3 2021 .dotnet/
drwxr-xr-x 2 xisun xisun 4096 Apr 26 2021 .landscape/
-rw------- 1 xisun xisun 32 May 21 2021 .lesshst
-rw-r--r-- 1 xisun xisun 0 Jan 25 10:26 .motd_shown
-rw-r--r-- 1 xisun xisun 807 Apr 26 2021 .profile
drwx------ 2 xisun xisun 4096 Jul 13 2021 .ssh/
-rw-r--r-- 1 xisun xisun 0 Apr 26 2021 .sudo_as_admin_successful
drwxr-xr-x 2 xisun xisun 4096 Jul 6 2021 .vim/
-rw------- 1 xisun xisun 9488 Jul 22 2021 .viminfo
drwxr-xr-x 5 xisun xisun 4096 Jun 3 2021 .vscode-server/
-rw-r--r-- 1 xisun xisun 183 Jan 14 10:08 .wget-hsts
-rw-rw-r-- 1 xisun xisun 14750 Jun 3 2021 get-docker.sh
drwxr-xr-x 15 xisun xisun 4096 Jan 25 10:32 miniconda3/
(base) xisun@DESKTOP-OM8IACS:~$ conda env list
# conda environments:
#
base * /home/xisun/miniconda3
(base) xisun@DESKTOP-OM8IACS:~$ conda create -n py38 python=3.8
Collecting package metadata (current_repodata.json): done
Solving environment: done
==> WARNING: A newer version of conda exists. <==
current version: 4.8.2
latest version: 4.11.0
Please update conda by running
$ conda update -n base -c defaults conda
## Package Plan ##
environment location: /home/xisun/miniconda3/envs/py38
added / updated specs:
- python=3.8
The following packages will be downloaded:
package | build
---------------------------|-----------------
_openmp_mutex-4.5 | 1_gnu 22 KB
ca-certificates-2021.10.26 | h06a4308_2 115 KB
certifi-2021.10.8 | py38h06a4308_2 152 KB
ld_impl_linux-64-2.35.1 | h7274673_9 586 KB
libffi-3.3 | he6710b0_2 50 KB
libgcc-ng-9.3.0 | h5101ec6_17 4.8 MB
libgomp-9.3.0 | h5101ec6_17 311 KB
libstdcxx-ng-9.3.0 | hd4cf53a_17 3.1 MB
ncurses-6.3 | h7f8727e_2 782 KB
openssl-1.1.1m | h7f8727e_0 2.5 MB
pip-21.2.4 | py38h06a4308_0 1.8 MB
python-3.8.12 | h12debd9_0 18.3 MB
readline-8.1.2 | h7f8727e_1 354 KB
setuptools-58.0.4 | py38h06a4308_0 790 KB
sqlite-3.37.0 | hc218d9a_0 999 KB
tk-8.6.11 | h1ccaba5_0 3.0 MB
wheel-0.37.1 | pyhd3eb1b0_0 33 KB
xz-5.2.5 | h7b6447c_0 341 KB
zlib-1.2.11 | h7f8727e_4 108 KB
------------------------------------------------------------
Total: 38.0 MB
The following NEW packages will be INSTALLED:
_libgcc_mutex pkgs/main/linux-64::_libgcc_mutex-0.1-main
_openmp_mutex pkgs/main/linux-64::_openmp_mutex-4.5-1_gnu
ca-certificates pkgs/main/linux-64::ca-certificates-2021.10.26-h06a4308_2
certifi pkgs/main/linux-64::certifi-2021.10.8-py38h06a4308_2
ld_impl_linux-64 pkgs/main/linux-64::ld_impl_linux-64-2.35.1-h7274673_9
libffi pkgs/main/linux-64::libffi-3.3-he6710b0_2
libgcc-ng pkgs/main/linux-64::libgcc-ng-9.3.0-h5101ec6_17
libgomp pkgs/main/linux-64::libgomp-9.3.0-h5101ec6_17
libstdcxx-ng pkgs/main/linux-64::libstdcxx-ng-9.3.0-hd4cf53a_17
ncurses pkgs/main/linux-64::ncurses-6.3-h7f8727e_2
openssl pkgs/main/linux-64::openssl-1.1.1m-h7f8727e_0
pip pkgs/main/linux-64::pip-21.2.4-py38h06a4308_0
python pkgs/main/linux-64::python-3.8.12-h12debd9_0
readline pkgs/main/linux-64::readline-8.1.2-h7f8727e_1
setuptools pkgs/main/linux-64::setuptools-58.0.4-py38h06a4308_0
sqlite pkgs/main/linux-64::sqlite-3.37.0-hc218d9a_0
tk pkgs/main/linux-64::tk-8.6.11-h1ccaba5_0
wheel pkgs/main/noarch::wheel-0.37.1-pyhd3eb1b0_0
xz pkgs/main/linux-64::xz-5.2.5-h7b6447c_0
zlib pkgs/main/linux-64::zlib-1.2.11-h7f8727e_4
Proceed ([y]/n)? y
Downloading and Extracting Packages
_openmp_mutex-4.5 | 22 KB | ############################################################################# | 100%
libgomp-9.3.0 | 311 KB | ############################################################################# | 100%
ld_impl_linux-64-2.3 | 586 KB | ############################################################################# | 100%
python-3.8.12 | 18.3 MB | ############################################################################# | 100%
zlib-1.2.11 | 108 KB | ############################################################################# | 100%
openssl-1.1.1m | 2.5 MB | ############################################################################# | 100%
libstdcxx-ng-9.3.0 | 3.1 MB | ############################################################################# | 100%
tk-8.6.11 | 3.0 MB | ############################################################################# | 100%
wheel-0.37.1 | 33 KB | ############################################################################# | 100%
sqlite-3.37.0 | 999 KB | ############################################################################# | 100%
setuptools-58.0.4 | 790 KB | ############################################################################# | 100%
pip-21.2.4 | 1.8 MB | ############################################################################# | 100%
libffi-3.3 | 50 KB | ############################################################################# | 100%
libgcc-ng-9.3.0 | 4.8 MB | ############################################################################# | 100%
ncurses-6.3 | 782 KB | ############################################################################# | 100%
certifi-2021.10.8 | 152 KB | ############################################################################# | 100%
readline-8.1.2 | 354 KB | ############################################################################# | 100%
xz-5.2.5 | 341 KB | ############################################################################# | 100%
ca-certificates-2021 | 115 KB | ############################################################################# | 100%
Preparing transaction: done
Verifying transaction: done
Executing transaction: done
#
# To activate this environment, use
#
# $ conda activate py38
#
# To deactivate an active environment, use
#
# $ conda deactivate
(base) xisun@DESKTOP-OM8IACS:~$ conda env list
# conda environments:
#
base * /home/xisun/miniconda3
py38 /home/xisun/miniconda3/envs/py38激活新创建的环境:
1
2(base) xisun@DESKTOP-OM8IACS:~$ conda activate py38
(py38) xisun@DESKTOP-OM8IACS:~$
安装模块:
pip 安装 pip-search:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123(base) xisun@DESKTOP-OM8IACS:~$ pip install pip_search
Collecting pip_search
Downloading pip_search-0.0.10-py3-none-any.whl (4.4 kB)
Collecting bs4
Downloading bs4-0.0.1.tar.gz (1.1 kB)
Collecting rich
Downloading rich-11.0.0-py3-none-any.whl (215 kB)
|████████████████████████████████| 215 kB 400 kB/s
Requirement already satisfied: requests in ./miniconda3/lib/python3.7/site-packages (from pip_search) (2.22.0)
Collecting beautifulsoup4
Downloading beautifulsoup4-4.10.0-py3-none-any.whl (97 kB)
|████████████████████████████████| 97 kB 346 kB/s
Collecting colorama<0.5.0,>=0.4.0
Downloading colorama-0.4.4-py2.py3-none-any.whl (16 kB)
Collecting commonmark<0.10.0,>=0.9.0
Downloading commonmark-0.9.1-py2.py3-none-any.whl (51 kB)
|████████████████████████████████| 51 kB 315 kB/s
Collecting typing-extensions<5.0,>=3.7.4; python_version < "3.8"
Downloading typing_extensions-4.0.1-py3-none-any.whl (22 kB)
Collecting pygments<3.0.0,>=2.6.0
Downloading Pygments-2.11.2-py3-none-any.whl (1.1 MB)
|████████████████████████████████| 1.1 MB 50 kB/s
Requirement already satisfied: certifi>=2017.4.17 in ./miniconda3/lib/python3.7/site-packages (from requests->pip_search) (2019.11.28)
Requirement already satisfied: idna<2.9,>=2.5 in ./miniconda3/lib/python3.7/site-packages (from requests->pip_search) (2.8)
Requirement already satisfied: urllib3!=1.25.0,!=1.25.1,<1.26,>=1.21.1 in ./miniconda3/lib/python3.7/site-packages (from requests->pip_search) (1.25.8)
Requirement already satisfied: chardet<3.1.0,>=3.0.2 in ./miniconda3/lib/python3.7/site-packages (from requests->pip_search) (3.0.4)
Collecting soupsieve>1.2
Downloading soupsieve-2.3.1-py3-none-any.whl (37 kB)
Building wheels for collected packages: bs4
Building wheel for bs4 (setup.py) ... done
Created wheel for bs4: filename=bs4-0.0.1-py3-none-any.whl size=1272 sha256=2811fe699e2c14aff05f0bbf8c2339c40e826130828a85461bb19160564c26c2
Stored in directory: /home/xisun/.cache/pip/wheels/0a/9e/ba/20e5bbc1afef3a491f0b3bb74d508f99403aabe76eda2167ca
Successfully built bs4
Installing collected packages: soupsieve, beautifulsoup4, bs4, colorama, commonmark, typing-extensions, pygments, rich, pip-search
Successfully installed beautifulsoup4-4.10.0 bs4-0.0.1 colorama-0.4.4 commonmark-0.9.1 pip-search-0.0.10 pygments-2.11.2 rich-11.0.0 soupsieve-2.3.1 typing-extensions-4.0.1
(base) xisun@DESKTOP-OM8IACS:~$ pip_search dotenv
🐍 https://pypi.org/search/?q=dotenv 🐍
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━┳━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┓
┃ Package ┃ Version ┃ Released ┃ Description ┃
┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━╇━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┩
│ 📂 dotenv │ 0.0.5 │ Mar 5, 2015 │ Handle .env files │
│ 📂 dotenv-config │ 0.1.4 │ Feb 8, 2019 │ Simple dotenv loader with the possibility of casting types │
│ 📂 typed-dotenv │ 1.0.1 │ Jul 30, 2020 │ Handle .env files with types │
│ 📂 python-dotenv │ 0.19.2 │ Nov 11, 2021 │ Read key-value pairs from a .env file and set them as │
│ │ │ │ environment variables │
│ 📂 dotenv-flow │ 0.2.3 │ Jan 3, 2022 │ Like the dotenv-flow NodeJS library, for Python │
│ 📂 py-dotenv │ 0.1 │ Dec 13, 2016 │ Read dotenv file │
│ 📂 dotenv-cli │ 2.2.0 │ Oct 30, 2020 │ Simple dotenv CLI. │
│ 📂 django-dotenv │ 1.4.2 │ Dec 11, 2017 │ foreman reads from .env. manage.py doesn't. Let's fix that. │
│ 📂 pythonsite-dotenv │ 0.1 │ Jun 30, 2014 │ Extend environment when invoking python │
│ 📂 firstclass-dotenv │ 0.0.6 │ Nov 18, 2020 │ Read value of .env(dotenv) into ENV values │
│ 📂 pytest-dotenv │ 0.5.2 │ Jun 16, 2020 │ A py.test plugin that parses environment files before running │
│ │ │ │ tests │
│ 📂 dotenv-linter │ 0.3.0 │ Dec 13, 2021 │ Linting dotenv files like a charm! │
│ 📂 dotenv-python │ 0.0.1 │ Jan 28, 2017 │ Read .env(-ish) configuration file for python web │
│ │ │ │ applications. │
│ 📂 xontrib-dotenv │ 0.1 │ Jun 15, 2016 │ Reads .env files into environment │
│ 📂 Flask-DotEnv │ 0.1.2 │ Apr 30, 2019 │ The .env file support for Flask │
│ 📂 dotenv-stripout │ 0.1.0 │ Aug 19, 2021 │ Strip secrets from .env files │
│ 📂 ssm-dotenv │ 0.1.0 │ Aug 8, 2019 │ manage project dotenv parameters in aws parameter store │
│ 📂 model-dotenv │ 0.0.0.1 │ Aug 2, 2021 │ A small example package │
│ 📂 enc-dotenv │ 0.0.3 │ Dec 12, 2019 │ encrypted env │
│ 📂 json-dotenv │ 0.0.21 │ Dec 19, 2019 │ json-dotenv │
│ 📂 python-dotenv-yaml │ 0.17.1 │ Jun 18, 2021 │ Read key-value pairs from a .env file and set them as │
│ │ │ │ environment variables -> with support for yaml syntax │
│ 📂 dotenv-settings-handler │ 0.0.3 │ Jul 5, 2019 │ Settings handler to load settings from a DotEnv file or system │
│ │ │ │ env variables, using python-dotenv and pydantic. │
│ 📂 py-sync-dotenv │ 0.1.1 │ Mar 19, 2021 │ Python Sync Dotenv is a Python package for synchronizing .env │
│ │ │ │ files across projects. │
│ 📂 poetry-dotenv-plugin │ 0.1.0a2 │ May 30, 2021 │ A Poetry plugin to automatically load environment variables │
│ │ │ │ from .env files │
│ 📂 msdss-base-dotenv │ 0.2.9 │ Nov 26, 2021 │ Environmental file management for the Modular Spatial Decision │
│ │ │ │ Support Systems (MSDSS) framework │
│ 📂 pytest-django-dotenv │ 0.1.2 │ Nov 26, 2019 │ Pytest plugin used to setup environment variables with │
│ │ │ │ django-dotenv │
│ 📂 ssm-dotenv-config │ 0.1.1 │ Jun 7, 2019 │ │
│ 📂 python-dotenv-run │ 0.1.4 │ Dec 23, 2017 │ Run command with environment populated by the .env file. │
│ 📂 dotenver │ 1.2.1 │ Jun 12, 2021 │ Automatically generate .env files from .env.example template │
│ │ │ │ files │
│ 📂 yaenv │ 1.6.1 │ Dec 14, 2021 │ Yet another dotenv parser for Python. │
│ 📂 pypiwrap │ 0.1.0 │ Mar 14, 2021 │ A simple wrapper for interfacing with PyPi APIs. │
│ 📂 env-validate │ 0.4 │ Jul 1, 2021 │ │
│ 📂 td-ameritrade-api │ 1.0.4 │ Oct 5, 2019 │ A python wrapper for the TD ameritrade API │
│ 📂 trashy-poetry │ 1.0.3 │ Mar 1, 2021 │ Poetry for everyday use │
│ 📂 dotenvy │ 0.2.0 │ Sep 20, 2017 │ Dotenv handler for Python │
│ 📂 envirun │ 0.0.1 │ Sep 25, 2021 │ Run any program with environment read from file │
│ 📂 TickerStore │ 0.0.8 │ Mar 22, 2019 │ Historical data of financial instruments from NSE │
│ 📂 configureme │ 0.1.2a0 │ Nov 4, 2018 │ Set up configuration for your application or library with │
│ │ │ │ ease. │
│ 📂 keyvault │ 0.1.5 │ Sep 21, 2021 │ A small package for handling project secrets │
│ 📂 envex │ 1.1.2 │ Oct 28, 2021 │ An extended os.environ interface │
└────────────────────────────┴─────────┴──────────────┴────────────────────────────────────────────────────────────────┘
(base) xisun@DESKTOP-OM8IACS:~$ pip list
Package Version
---------------------- -------------------
asn1crypto 1.3.0
beautifulsoup4 4.10.0
bs4 0.0.1
certifi 2019.11.28
cffi 1.14.0
chardet 3.0.4
colorama 0.4.4
commonmark 0.9.1
conda 4.8.2
conda-package-handling 1.6.0
cryptography 2.8
idna 2.8
pip 20.0.2
pycosat 0.6.3
pycparser 2.19
Pygments 2.11.2
pyOpenSSL 19.1.0
PySocks 1.7.1
requests 2.22.0
rich 11.0.0
ruamel-yaml 0.15.87
setuptools 45.2.0.post20200210
six 1.14.0
soupsieve 2.3.1
tqdm 4.42.1
typing-extensions 4.0.1
urllib3 1.25.8
wheel 0.34.2pipx 安装 pip-search:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35(py38) xisun@DESKTOP-OM8IACS:/etc/apt$ pip install pipx
Collecting pipx
Downloading pipx-1.0.0-py3-none-any.whl (54 kB)
|████████████████████████████████| 54 kB 47 kB/s
Collecting packaging>=20.0
Downloading packaging-21.3-py3-none-any.whl (40 kB)
|████████████████████████████████| 40 kB 337 kB/s
Collecting userpath>=1.6.0
Downloading userpath-1.7.0-py2.py3-none-any.whl (14 kB)
Collecting argcomplete>=1.9.4
Downloading argcomplete-2.0.0-py2.py3-none-any.whl (37 kB)
Collecting pyparsing!=3.0.5,>=2.0.2
Downloading pyparsing-3.0.7-py3-none-any.whl (98 kB)
|████████████████████████████████| 98 kB 416 kB/s
Collecting click
Downloading click-8.0.3-py3-none-any.whl (97 kB)
|████████████████████████████████| 97 kB 537 kB/s
Installing collected packages: pyparsing, click, userpath, packaging, argcomplete, pipx
Successfully installed argcomplete-2.0.0 click-8.0.3 packaging-21.3 pipx-1.0.0 pyparsing-3.0.7 userpath-1.7.0
(py38) xisun@DESKTOP-OM8IACS:/etc/apt$ pipx install pip-search
installed package pip-search 0.0.10, installed using Python 3.8.12
These apps are now globally available
- pip_search
⚠️ Note: '/home/xisun/.local/bin' is not on your PATH environment variable. These apps will not be globally
accessible until your PATH is updated. Run `pipx ensurepath` to automatically add it, or manually modify your PATH
in your shell's config file (i.e. ~/.bashrc).
done! ✨ 🌟 ✨
(py38) xisun@DESKTOP-OM8IACS:/etc/apt$ pipx ensurepath
Success! Added /home/xisun/.local/bin to the PATH environment variable.
Consider adding shell completions for pipx. Run 'pipx completions' for instructions.
You will need to open a new terminal or re-login for the PATH changes to take effect.
Otherwise pipx is ready to go! ✨ 🌟 ✨- 重新打开 terminal,即可使用 pip-search 命令。
pip 设置镜像源:
1
pip config set global.index-url https://mirrors.aliyun.com/pypi/simple/
Python 解释器
- 当编写 Python 代码时,得到的是一个包含 Python 代码的以
.py为扩展名的文本文件。要运行代码,就需要 Python 解释器去执行.py文件。 - 由于整个 Python 语言从规范到解释器都是开源的,所以理论上,只要水平够高,任何人都可以编写 Python 解释器来执行 Python 代码(当然难度很大)。事实上,确实存在多种 Python 解释器。
- Python 的解释器很多,但使用最广泛的还是 CPython。如果要和 Java 或 .Net 平台交互,最好的办法不是用 Jython 或 IronPython,而是通过网络调用来交互,确保各程序之间的独立性。
CPython
- 从 Python 官网下载并安装好 Python 3.x 后,我们就直接获得了一个官方版本的解释器:CPython。这个解释器是用 C 语言开发的,所以叫 CPython。在命令行下运行
python命令就是启动 CPython 解释器。 - CPython 是使用最广的 Python 解释器。
IPython
- IPython 是基于 CPython 之上的一个交互式解释器,也就是说,IPython 只是在交互方式上有所增强,但是执行 Python 代码的功能和 CPython 是完全一样的。好比很多国产浏览器虽然外观不同,但内核其实都是调用了 IE。
- CPython 用
>>>作为提示符,而 IPython 用In [序号]:作为提示符。
PyPy
- PyPy 是另一个 Python 解释器,它的目标是执行速度。PyPy 采用 JIT 技术,对 Python 代码进行动态编译(注意不是解释),所以可以显著提高 Python 代码的执行速度。
- 绝大部分 Python 代码都可以在 PyPy 下运行,但是 PyPy 和 CPython 有一些是不同的,这就导致相同的 Python 代码在两种解释器下执行可能会有不同的结果。如果你的代码要放到 PyPy 下执行,就需要了解 PyPy和CPython的不同点。
Jython
- Jython 是运行在 Java 平台上的 Python 解释器,可以直接把 Python 代码编译成 Java 字节码执行。
IronPython
- IronPython 和 Jython 类似,只不过 IronPython 是运行在微软 .Net 平台上的 Python 解释器,可以直接把 Python 代码编译成 .Net 字节码。
Python 基础
Python 的语法比较简单,采用缩进方式,写出来的代码就像下面的样子:
1
2
3
4
5
6# print absolute value of an integer:
a = 100
if a >= 0:
print(a)
else:
print(-a)Python 程序是大小写敏感的,如果写错了大小写,程序会报错。
Python 中的每一行就是一条语句,每条语句以换行结束,每一行语句不要过长(规范中建议每行不要超过 80 个字符)。当语句以冒号
:结尾时,缩进的语句视为代码块。Python 一条语句可以分多行编写,多行编写时语句后边以
\结尾。Python 是缩进严格的语言,所以在 Python 中不要随便写缩进。按照约定俗成的惯例,应该始终坚持使用 4 个空格的缩进。当重构代码时,粘贴过去的代码必须重新检查缩进是否正确。此外,IDE 很难像格式化 Java 代码那样格式化 Python 代码。
Python 中使用
#来表示注释,#后的内容都属于注释,注释的内容将会被解释器所忽略。注释要求简单明了,一般习惯上#后边会跟着一个空格。
字面量和变量
字面量就是一个一个的值,比如:
1,2,3,4,5,6,‘HELLO’。字面量所表示的意思就是它的字面的值,在程序中可以直接使用字面量。变量(variable)可以用来保存字面量,并且变量中保存的字面量是不定的。变量本身没有任何意思,它会根据不同的字面量表示不同的意思。
在 Python 中,等号是赋值语句,可以把任意数据类型赋值给变量,同一个变量可以反复赋值,而且可以是不同类型的变量。
1
2
3
4a = 123 # a是整数
print(a) # 123
a = 'ABC' # a变为字符串
print(a) # ABC- 这种变量本身类型不固定的语言称之为动态语言,与之对应的是静态语言。静态语言在定义变量时必须指定变量类型,如果赋值的时候类型不匹配,就会报错。例如 Java 是静态语言。
等号也可以把一个变量
a赋值给另一个变量b,这个操作实际上是把变量b指向变量a所指向的数据。1
2
3
4a = 'ABC'
b = a
a = 'XYZ'
print(b) # ABC,不是XYZ常量就是不能变的变量,比如常用的数学常数 π 就是一个常量。在 Python 中,通常用全部大写的变量名表示常量:
1
PI = 3.14159265359
- 事实上
PI仍然是一个变量,Python 根本没有任何机制保证PI不会被改变,所以,用全部大写的变量名表示常量只是一个习惯上的用法,如果你一定要改变变量PI的值,也没人能拦住你。
- 事实上
一般在开发时,很少直接使用字面量,都是将字面量保存到变量中,通过变量来引用字面量。
变量和标识符
- Python 中使用变量,不需要声明,直接为变量赋值即可。
- Python 中不能使用没有进行过赋值的变量,如果使用没有赋值过的变量,会报错
NameError: name 'b' is not defined。 - Python 是一个动态类型的语言,可以为变量赋任意类型的值,也可以任意修改变量的值。
- Python 中所有可以自主命名的内容都属于标识符,比如变量名、函数名、类名。
- 标识符必须遵循标识符的规范:
- 标识符中可以含有字母、数字、
_,但是不能使用数字开头。 - 标识符不能是 Python 中的关键字和保留字,也不建议使用 Python 中的函数名作为标识符,因为这样会导致函数被覆盖。
- 在 Python 中注意遵循两种命名规范:
- 下划线命名法:所有字母小写,单词之间使用
_分割。如:max_length、min_length、hello_world。 - 帕斯卡命名法:大驼峰命名法,首字母大写,每个单词开头字母大写,其余字母小写。如:MaxLength、MinLength、HelloWorld。
- 下划线命名法:所有字母小写,单词之间使用
- 如果使用不符合标准的标识符,会报错
SyntaxError: invalid syntax。
- 标识符中可以含有字母、数字、
数据类型
- 数据类型指的就是变量的值的类型,也就是可以为变量赋哪些值。
数值
- Python 中,数值分成了三种:整数、浮点数(小数)、复数。
整数
- Python中,所有的整数都是 int 类型。
- Python 可以处理任意大小的整数,包括负整数,在程序中的表示方法和数学上的写法一模一样,例如:
1,100,-8080,0,等等。- Python 的整数没有大小限制,而某些语言的整数根据其存储长度是有大小限制的,例如 Java 对 32 位整数的范围限制在 -2147483648 ~ 2147483647。
- 对于很大的数,例如
10000000000,很难数清楚 0 的个数。Python 允许在数字中间以_分隔,因此,写成10_000_000_000和10000000000是完全一样的。十六进制数也可以写成0xa1b2_c3d4。 - 计算机由于使用二进制,所以,有时候用十六进制表示整数比较方便,十六进制用
0x前缀和 0 - 9,a - f 表示,例如:0xff00,0xa5b4c3d2,等等。- 十进制的数,不能以 0 开头。二进制以
0b开头,八进制以0o开头,十六进制以0x开头。 - 其他进制的整数,只要是数字,打印时一定是以十进制的形式显示的。
- 十进制的数,不能以 0 开头。二进制以
浮点数
Python 中,所有的浮点数都是 float 类型。
浮点数也就是小数,之所以称为浮点数,是因为按照科学记数法表示时,一个浮点数的小数点位置是可变的,比如,
1.23 x 10^9和12.3 x 10^8是完全相等的。浮点数可以用数学写法,如1.23,3.14,-9.01,等等。但是对于很大或很小的浮点数,就必须用科学计数法表示,把 10 用 e 替代,1.23 x 10^9就是1.23e9,或者12.3e8,0.000012可以写成1.2e-5,等等。- Python 的浮点数也没有大小限制,但是超出一定范围就直接表示为
inf(无限大)。
- Python 的浮点数也没有大小限制,但是超出一定范围就直接表示为
整数和浮点数在计算机内部存储的方式是不同的,整数运算永远是精确的(除法难道也是精确的?是的!),而浮点数运算则可能会有四舍五入的误差,得到一个不精确的结果。
在Python中,有两种除法,一种除法是
/,/除法的计算结果是浮点数,即使是两个整数恰好整除,结果也是浮点数。1
2
3
4>>> 10 / 3
3.3333333333333335
>>> 9 / 3
3.0还有一种除法是
//,称为地板除,//除法只取结果的整数部分。1
2
3
4>>> 10 // 3
3
>>> 9 // 3
3相对于取整运算,Python 还提供一个余数运算,可以得到两个整数相除的余数。
1
2
3
4>>> 10 % 3
1
>>> 9 % 3
0无论整数做
//除法还是取余数,结果永远是整数,所以,整数运算结果永远是精确的。
字符串
字符串用来表示一段文本信息,字符串是程序中使用的最多的数据类型。
字符串是以单引号
'或双引号"括起来的任意文本(不要混用),比如'abc',"xyz"等等。请注意,''或""本身只是一种表示方式,不是字符串的一部分,因此,字符串'abc'只有a,b,c这 3 个字符。如果'本身也是一个字符,那就可以用""括起来,比如"I'm OK"包含的字符是I,',m,空格,O,K这 6 个字符。相同的引号之间不能嵌套。如果字符串内部既包含
'又包含",可以用转义字符\来标识,比如'I\'m \"OK\"!'。转义字符
\可以转义很多字符。比如:\t 表示制表符,\n 表示换行符,\uxxxx表示 Unicode 编码,可以打印出一些特殊的符号。1
2
3
4
5
6
7
8>>> print('I\'m ok.')
I'm ok.
>>> print('I\'m learning\nPython.')
I'm learning
Python.
>>> print('\\\n\\')
\
\如果字符串里面有很多字符都需要转义,就需要加很多
\,为了简化,Python 还允许用r''表示 ‘ ‘ 内部的字符串默认不转义。1
2
3
4>>> print('\\\t\\')
\ \
>>> print(r'\\\t\\')
\\\t\\如果字符串内部有很多换行,用
\n写在一行里不好阅读,为了简化,Python 允许用'''...'''或"""..."""的格式表示多行内容。三重引号中可以换行,并且会保留字符串中的格式。1
2
3
4
5
6
7
8
9
10>>> print('''line1
... line2
... line3''')
line1
line2
line3
>>> print(r'''hello,\n
... world''')
hello,\n
world- 上面是在交互式命令行内输入,在输入多行内容时,提示符由
>>>变为...,提示可以接着上一行输入,注意...是提示符,不是代码的一部分。
- 上面是在交互式命令行内输入,在输入多行内容时,提示符由
格式化字符串:
拼串:字符串之间可以进行加法运算,如果将两个字符串进行相加,则会自动将两个字符串拼接为一个。
1
2
3name = '孙悟空'
print('欢迎 ' + name + ' 光临!') # 欢迎 孙悟空 光临!多参数:字符串只能和字符串拼接,不能和其他的类型进行加法运算。
print("a = " + a)这种写法在 Python 中不常见,因为 a 可能不是字符串,容易出错,常写作print('a = ', a)。1
2
3name = '孙悟空'
print('欢迎', name, '光临!') # 欢迎 孙悟空 光临!占位符:在创建字符串时,可以在字符串中指定占位符:
%s在字符串中表示任意字符,%f表示浮点数占位符,%d表示整数占位符。1
2
3
4
5
6
7
8b = 'Hello %s' % '孙悟空' # 一个占位符:Hello 孙悟空
b = 'hello %s 你好 %s' % ('tom', '孙悟空') # 两个占位符:hello tom 你好 孙悟空
b = 'hello %3s' % 'ab' # 占位符处的字符串长度至少为3,不足3的,在前面填充空格:hello ab
b = 'hello %3.5s' % 'abcdefg' # 占位符处的字符串的长度限制在3-5之间:hello abcde
b = 'hello %.2f' % 123.456 # 保留2位小数,四舍五入:hello 123.46
b = 'hello %d' % 123.95 # 直接舍弃小数位:hello 123
print(b)格式化字符串:可以通过在字符串前添加一个
f来创建一个格式化字符串,在格式化字符串中可以直接嵌入变量。1
2
3
4
5
6a = 123
b = '呵呵'
c = f'hello {a} {b}'
print(f'a = {a}') # a = 123
print(c) # hello 123 呵呵
字符串的复制:将字符串和数字相乘。
*在语言中表示乘法,如果将字符串和数字相乘,则解释器会将字符串重复指定的次数并返回。1
2
3
4a = 'abc'
a = a * 5
print(a) # abcabcabcabcabc
布尔值
布尔值和布尔代数的表示完全一致,一个布尔值只有
True、False两种值,要么是True,要么是False,在 Python 中,可以直接用True、False表示布尔值(请注意大小写),也可以通过布尔运算计算出来。1
2
3
4
5
6
7
8>>> True
True
>>> False
False
>>> 3 > 2
True
>>> 2 > 5
False布尔值可以用
and、or和not运算。and运算是与运算,只有所有都为True,and运算结果才是True:1
2
3
4
5
6
7
8
9
10>>> True and True
True
>>> True and False
False
>>> False and True
False
>>> False and False
False
>>> 5 > 3 and 3 > 1
Trueor运算是或运算,只要其中有一个为True,or运算结果就是True:1
2
3
4
5
6
7
8
9
10>>> True or True
True
>>> True or False
True
>>> False or True
True
>>> False or False
False
>>> 5 > 3 or 1 > 3
Truenot运算是非运算,它是一个单目运算符,把True变成False,False变成True:1
2
3
4
5
6>>> not True
False
>>> not False
True
>>> not 5 > 3
False
布尔值经常用在条件判断中,比如:
1
2
3
4if age >= 18:
print('adult')
else:
print('teenager')布尔值实际上也属于整型,
True就相当于 1,False就相当于 0。1
2print(1 + False) # 1
print(1 + True) # 2
空值
- 空值是 Python 里一个特殊的值,用
None表示。None不能理解为 0,因为 0 是有意义的,而None是一个特殊的空值。
类型检查
通过类型检查,可以检查变量对应的值的类型。
type()用来检查值的类型,该函数会将检查的结果作为返回值返回,可以通过变量来接收函数的返回值。1
2
3
4
5
6
7
8
9
10
11
12
13a = 123 # 数值
b = '123' # 字符串
print(type(a)) # <class 'int'>
print(type(b)) # <class 'str'>
c = type(a)
print(c) # <class 'int'>
c = type('123')
print(c) # <class 'str'>
print(type(1)) # <class 'int'>
print(type(1.5)) # <class 'float'>
print(type(True)) # <class 'bool'>
print(type('hello')) # <class 'str'>
print(type(None)) # <class 'NoneType'>
对象
- Python 是一门面向对象的语言。
- 一切皆对象!
- 程序运行当中,所有的数据都是存储到内存当中然后再运行的!
- 对象就是内存中专门用来存储指定数据的一块区域。
- 对象实际上就是一个容器,专门用来存储数据。
- 像我们之前学习的数值、字符串、布尔值、None 都是对象。
对象的结构
每个对象中都要保存三种数据:
id(标识)
id 用来标识对象的唯一性,每一个对象都有唯一的 id。
对象的 id 就相当于人的身份证号一样。
可以通过
id()函数来查看对象的 id。1
2print(id(123)) # 140708231919200
print(id('a')) # 2270491024176id 是由解析器生成的,在 CPython 中,id 就是对象的内存地址。
对象一旦创建,则它的 id 永远不能再改变。
type(类型)
类型用来标识当前对象所属的类型,比如:int,str,float,bool。
类型决定了对象有哪些功能。
通过
type()函数来查看对象的 type。1
2print(type(123)) # <class 'int'>
print(type('a')) # <class 'str'>Python 是一门强类型的语言,对象一旦创建类型便不能修改。
value(值)
- 值就是对象中存储的具体的数据。
- 对于有些对象,值是可以改变的。
- 对象分成两大类:可变对象和不可变对象。
- 可变对象的值可以改变。
- 不可变对象的值不能改变,之前学习的数值、字符串等都是不可变对象。
变量和对象
对象并没有直接存储到变量中,在 Python 中变量更像是给对象起了一个别名。
变量中存储的不是对象的值,而是对象的 id(内存地址),当我们使用变量时,实际上就是在通过对象 id 在查找对象。
变量中保存的对象,只有在为变量重新赋值时才会改变。
变量和变量之间是相互独立的,修改一个变量不会影响另一个变量。
1
2
3
4
5
6
7
8
9print(a) # 10
print(b) # 10
print(id(a)) # 140708432125984
print(id(b)) # 140708432125984
a = 456
print(a) # 456
print(b) # 10
print(id(a)) # 2898418807216
print(id(b)) # 140708432125984
类型转换
所谓的类型转换,是将一个类型的对象转换为其他对象。
类型转换不是改变对象本身的类型,而是根据当前对象的值来创建一个新对象。
类型转换四个函数:
int(),float(),str(),bool()。int()可以用来将其他的对象转换为整型。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23a = True
a = int(a)
print(a) # 1
a = False
a = int(a)
print(a) # 0
a = '123'
a = int(a)
print(a) # 123
a = 11.6
a = int(a)
print(a) # 11
a = '11.5'
a = int(a) # ValueError
print(a)
a = None
a = int(a) # TypeError
print(a)- 布尔值:True —> 1,False —> 0。
- 浮点数:直接取整,省略小数点后的内容。
- 字符串:如果是一个合法的整数字符串,则直接转换为对应的数字。如果不是一个合法的整数字符串,则报错
ValueError: invalid literal for int() with base 10: '11.5'。 - 对于其他不可转换为整型的对象,直接抛出异常
TypeError。 int()函数不会对原来的变量产生影响,他是将对象转换为指定的类型并将其作为返回值返回,如果希望修改原来的变量,则需要对变量进行重新赋值。
float()和int()基本一致,不同的是它会将对象转换为浮点数。1
2
3
4
5
6
7
8
9
10
11a = 1
a = float(a)
print(a) # 1.0
a = False
a = float(a)
print(a) # 0.0
a = True
a = float(a)
print(a) # 1.0str()可以将对象转换为字符串。1
2
3
4
5
6a = 123
a = str(a)
print(a) # 123
b = 456
print('hello' + str(b)) # hello456- True —> ‘True’。
- False —> ‘False’。
- 123 —> ‘123’ 。
- 。。。
bool()可以将对象转换为布尔值,任何对象都可以转换为布尔值。1
2
3
4
5
6
7
8
9
10
11a = None
a = bool(a)
print(a) # False
a = 0
a = bool(a)
print(a) # False
a = ''
a = bool(a)
print(a) # False- 规则:对于所有表示空性的对象都会转换为 False,其余的转换为 True。表示空性的对象:
0、None、''等。
- 规则:对于所有表示空性的对象都会转换为 False,其余的转换为 True。表示空性的对象:
运算符(操作符)
- 运算符可以对一个值或多个值进行运算或各种操作。比如
+、-、=都属于运算符。 - 常用运算符的分类:
- 算术运算符
- 赋值运算符
- 关系运算符(比较运算符)
- 逻辑运算符
- 条件运算符(三元运算符)
算术运算符
1 | # 加法运算符 |
加法运算符:
+。如果是两个字符串之间进行加法运算,则会进行拼串操作。减法运算符:
-。乘法运算符:
*。如果将字符串和数字相乘,则会对字符串进行复制操作,将字符串重复指定次数。除法运算符:
/。运算时结果总会返回一个浮点类型。幂运算:
**。求一个值的几次幂。整除:
//。向下取整,只会保留计算后的整数位,总会返回一个整型。取模:
%。即取余,求两个数相除的余数。运算时,注意正负号的问题。
在对浮点数做算术运算时,结果也会返回一个浮点数。
1
2b = 25.0 / 5
print(b) # 5.0
赋值运算符
- 赋值运算符
=可以将等号右侧的值赋值给等号左侧的变量。 +=:a += 5相当于a = a + 5。-=:a -= 5相当于a = a - 5。*=:a *= 5相当于a = a * 5。/=:a /= 5相当于a = a / 5。**=:a **= 5相当于a = a ** 5。//=:a //= 5相当于a = a // 5。%=:a %= 5相当于a = a % 5。
关系运算符(比较运算符)
1 | result = 10 > 20 # False |
- 关系运算符用来比较两个值之间的关系,总会返回一个布尔值。如果关系成立,返回 True,否则返回 False。
>:比较左侧值是否大于右侧值。>=:比较左侧的值是否大于或等于右侧的值。<:比较左侧值是否小于右侧值。<=:比较左侧的值是否小于或等于右侧的值。==:比较两个对象的值是否相等,比较的是对象的值。!=:比较两个对象的值是否不相等,比较的是对象的值。is:比较两个对象是否是同一个对象,比较的是对象的 id。is not:比较两个对象是否不是同一个对象,比较的是对象的 id。
逻辑运算符
逻辑运算符主要用来做一些逻辑判断。
and:逻辑与。and可以对符号两侧的值进行与运算。只有在符号两侧的值都为 True 时,才会返回 True,只要有一个 False 就返回 False。
Python 中的与运算是短路的与,如果第一个值为 False,则不再看第二个值,直接返回 False。
1
2True and print('男:你猜我出来吗?') # 第一个值是True,会看第二个值,所以print()会执行
False and print('女:你猜我出来吗?') # 第一个值是False,不会看第二个值,所以print()不会执行
or:逻辑或。or可以对符号两侧的值进行或运算。或运算两个值中只要有一个 True,就会返回 True。
Python 中的或运算是短路的或,如果第一个值为 True,则不再看第二个值,直接返回 True。
1
2False or print('男:你猜我出来吗?') # 第一个值为False,继续看第二个,所以打印语句执行
True or print('女:你猜我出来吗?') # 第一个值为True,不看第二个,所以打印语句不执行
not:逻辑非。not可以对符号右侧的值进行非运算。- 对于布尔值,非运算会对其进行取反操作,True 变 False,False 变 True。
- 对于非布尔值,非运算会先将其转换为布尔值,然后再取反。
非布尔值的与或运算:当我们对非布尔值进行与或运算时,Python 会将其当做布尔值运算,最终会返回原值。
与运算的规则:
1
2
3
4
5
6
7
8
9
10
11# True and True
result = 1 and 2 # 2
# True and False
result = 1 and 0 # 0
# False and True
result = 0 and 1 # 0
# False and False
result = None and 0 # None- 与运算是找 False 的,如果第一个值是 False,则不看第二个值。
- 如果第一个值是 False,则直接返回第一个值,否则返回第二个值。
或运算的规则:
1
2
3
4
5
6
7
8
9
10
11# True or True
result = 1 or 2 # 1
# True or False
result = 1 or 0 # 1
# False or True
result = 0 or 1 # 1
# False or False
result = None or 0 # 0- 或运算是找 True 的,如果第一个值是 True,则不看第二个值。
- 如果第一个值是 True,则直接返回第一个值,否则返回第二个值。
条件运算符(三元运算符)
1 | a = 30 |
语法:
语句1 if 条件表达式 else 语句2。na = input(‘请输入任意内容:’)
print(‘用户输入的内容是:’, a)获取用户输入的用户名
username = input(‘请输入你的用户名: ‘)
判断用户名是否是admin
if username == ‘admin’:
print('欢迎管理员光临!')该函数用来获取用户的输入。
input()调用后,程序会立即暂停,等待用户输入,用户输入完内容以后,点击回车程序才会继续向下执行。用户输入完成以后,其所输入的的内容会以返回值的形式返回。注意:
input()的返回值是一个字符串。input()函数中可以设置一个字符串作为参数,这个字符串将会作为提示文字显示。input()也可以用于暂时阻止程序结束。
Python 流程控制语句
- Python代码在执行时是按照自上向下顺序执行的。
- 通过流程控制语句,可以改变程序的执行顺序,也可以让指定的程序反复执行多次。
- 流程控制语句分成两大类:条件判断语句,循环语句。
条件判断语句(if 语句)
1 | num = 10 |
语法:
1
2if 条件表达式:
代码块执行的流程:if 语句在执行时,会先对条件表达式进行求值判断,如果为 True,则执行 if 后的语句;如果为 False,则不执行。
默认情况下,if 语句只会控制紧随其后的那条语句,如果希望 if 可以控制多条语句,则可以在 if 后跟着一个代码块。
代码块:
- 代码块中保存着一组代码,同一个代码块中的代码,要么都执行要么都不执行。
- 代码块就是一种为代码分组的机制。
- 如果要编写代码块,语句就不能紧随在
:后边,而是要写在下一行。 - 代码块以缩进开始,直到代码恢复到之前的缩进级别时结束。
- 缩进有两种方式,一种是使用 tab 键,一种是使用空格(四个)。
- Python 代码中使用的缩进方式必须统一。
- Python 的官方文档中推荐我们使用空格来缩进。
可以使用逻辑运算符来连接多个条件,如果希望所有条件同时满足,则需要使用
and;如果希望只要有一个条件满足即可,则需要使用or。
if - else
1 | age = 7 |
语法:
1
2
3
4if 条件表达式:
代码块1
else:
代码块2执行流程:if - else 语句在执行时,先对 if 后的条件表达式进行求值判断,如果为 True,则执行 if 后的代码块 1;如果为 False,则执行 else 后的代码块 2。
if - elif - else
1 | age = 210 |
语法:
1
2
3
4
5
6
7
8if 条件表达式:
代码块
elif 条件表达式:
代码块
elif 条件表达式:
代码块
else:
代码块执行流程:if - elif - else 语句在执行时,会自上向下依次对条件表达式进行求值判断,如果表达式的结果为 True,则执行当前代码块,然后语句结束;如果表达式的结果为 False,则继续向下判断,直到找到 True 为止;如果所有的表达式都是 False,则执行 else 后的代码块。
if - elif - else 中只会有一个代码块会执行。
循环语句
- 循环语句可以使指定的代码块重复指定的次数。
- 循环语句分成两种,while 循环和 for 循环。
while 循环
1 | # 创建一个执行十次的循环 |
语法:
1
2
3
4while 条件表达式:
代码块
else:
代码块执行流程:while 语句在执行时,会先对 while 后的条件表达式进行求值判断,如果判断结果为 True,则执行循环体(代码块),循环体执行完毕,继续对条件表达式进行求值判断,以此类推,直到判断结果为 False,则循环终止,如果循环有对应的 else,则执行 else 后的代码块。
条件表达式恒为 True 的循环语句,称为死循环。
循环的三个要件:
- 初始化表达式:通过初始化表达式初始化一个变量。
- 条件表达式:条件表达式用来设置循环执行的条件。
- 更新表达式:修改初始化变量的值。
循环嵌套
打印图形:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42# 在控制台中打印如下图形
# *****
# *****
# *****
# *****
# *****
#
# 创建一个循环来控制图形的高度
# 循环嵌套时,外层循环没执行一次,内存循环就要执行一圈
i = 0
while i < 5:
# 创建一个内层循环来控制图形的宽度
j = 0
while j < 5:
# print()默认在结尾打印\n换行符,添加end参数,打印时不要换行
print("* ", end='')
j += 1
# 每一行打印完毕后,再打印一个换行符
print()
i += 1
#
# * j<1 i=0
# ** j<2 i=1
# *** j<3 i=2
# **** j<4 i=3
# ***** j<5 i=4
#
# *****
# ****
# ***
# **
# *
i = 0
while i < 5:
j = 0
while j < i + 1:
print("* ", end='')
j += 1
print()
i += 199 乘法表:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18# 打印99乘法表
# 1*1=1
# 1*2=2 2*2=4
# 1*3=3 2*3=6 3*3=9
# ... 9*9=81
# 创建一个外层循环来控制图形的高度
i = 0
while i < 9:
i += 1
# 创建一个内层循环来控制图形的宽度
j = 0
while j < i:
j += 1
print(f"{j}*{i}={i*j} ",end="")
print()
break 和 continue
1 | i = 0 |
- break 可以用来立即退出循环语句(包括 else)。
- continue 可以用来跳过当次循环。
- break 和 continue 都是只对离他最近的循环起作用。
- pass 是用来在判断或循环语句中占位的,无实际意义。如果循环体内容没想好怎么写,可以先用 pass 占位,这样不会影响程序执行。
模块引入
1 | # 模块,通过模块可以对Python进行扩展 |
for 循环
语法:
1
2for 变量 in 序列 :
代码块for 循环除了创建方式以外,其余的都和 while 循环一样,包括 else、break、continue 都可以在 for 循环中使用。
Python 数据结构
序列(sequence)
计算机中数据存储的方式叫数据结构,序列是 Python 中最基本的一种数据结构。
序列用于保存一组有序的数据,所有的数据在序列当中都有一个唯一的位置(索引),并且序列中的数据会按照添加的顺序来分配索引。
序列存储的数据,称为元素。
序列的分类:
- 可变序列(序列中的元素可以改变)
- 列表(list)
- 不可变序列(序列中的元素不能改变)
- 元组(tuple)
- 字符串(str)
- 可变序列(序列中的元素可以改变)
range()函数:用来生成一个自然数的序列。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15# range()是一个函数,可以用来生成一个自然数的序列
# 该函数需要三个参数
# 1.起始位置(包含,可以省略,默认是0)
# 2.结束位置(不包含)
# 3.步长(可以省略,默认是1)
r = range(5)
print(list(r)) # [0, 1, 2, 3, 4]
r = range(0, 10, 2)
print(list(r)) # [0, 2, 4, 6, 8]
r = range(10, 0, -1)
print(list(r)) # [10, 9, 8, 7, 6, 5, 4, 3, 2, 1]
# 通过range()可以创建一个执行指定次数的for循环
for i in range(30):
print(i)
通用操作
+可以将两个序列拼接为一个序列。*可以将序列重复指定的次数。in用来检查指定元素是否存在于序列中,如果存在,返回 True,否则返回 False。not in用来检查指定元素是否不在序列中,如果不在,返回 True,否则返回 False。len()函数获取序列的长度,即序列中的元素的个数。该长度值,是序列的最大索引加 1。min()函数获取序列中的最小值。max()函数获取序列中的最大值。- 可以通过索引(index)来获取序列中的元素:
- 语法:
序列[索引]。 - 索引是元素在序列中的位置,序列中的每一个元素都有一个索引。
- 索引是从 0 开始的整数,序列第一个位置索引为 0,第二个位置索引为 1,第三个位置索引为 2,以此类推。
- 索引可以是负数,表示从后向前获取元素,-1 表示倒数第一个元素,-2 表示倒数第二个元素,以此类推。
- 如果使用的索引超过了序列最大的范围,会抛出异常
IndexError: list index out of range。
- 语法:
s.index()方法获取指定元素在序列中的第一次出现时索引。- 方法和函数基本上是一样,只不过方法必须通过
对象.方法()的形式调用,方法实际上就是和对象关系紧密的函数。 index()的第二个参数,表示查找的起始位置,第三个参数,表示查找的结束位置。- 如果要获取序列中没有的元素,会抛出异常。
- 方法和函数基本上是一样,只不过方法必须通过
s.count()方法统计指定元素在序列中出现的次数。
切片
- 切片指从现有序列中,获取一个子序列。
- 语法一:
序列[起始:结束]。- 通过切片获取元素时,会包括起始位置的元素,不会包括结束位置的元素。
- 做切片操作时,总会返回一个新的序列,但不会影响原来的序列。
- 起始和结束位置的索引都可以省略不写。
- 如果省略起始位置,则会从第一个元素开始截取。
- 如果省略结束位置,则会一直截取到最后。
- 如果起始位置和结束位置全部省略,则相当于创建了一个序列的副本。
- 语法二:
序列[起始:结束:步长]。- 步长表示,每次获取元素的间隔,默认值是 1。
- 步长不能是 0,但可以是负数。
- 步长如果是负数,则从序列的后边向前边取元素。
分类
列表(list)
列表是 Python 中的一个对象。
对象(object)就是内存中专门用来存储数据的一块区域,之前我们学习的对象,像数值,它只能保存一个单一的数据。
列表是用来存储对象的对象,列表中可以保存多个有序的数据。
列表中可以保存任意的对象,但一般不会这样操作,尽可能保证列表中元素属性一致。
列表的创建
1
2
3
4
5
6
7
8
9
10
11
12
13
14my_list = [] # 创建了一个空列表
print(my_list, type(my_list)) # [] <class 'list'>
my_list = [10] # 创建一个只包含一个元素的列表
my_list = [10, 20, 30, 40, 50] # 创建了一个包含有5个元素的列表
# my_list = [10, 'hello', True, None, [1, 2, 3], print] # 列表可以保存任意对象,但一般不会这样操作
print(my_list[4]) # 50
print((my_list[-2])) # 40
print(len(my_list)) # 5- 使用
[]来创建列表。
- 使用
- 一个列表中可以存储多个元素,也可以在创建列表时,来指定列表中的元素。
- 当向列表中添加多个元素时,多个元素之间使用
,隔开。
- 列表中的对象都会按照插入的顺序存储到列表中,第一个插入的对象保存到第一个位置,第二个保存到第二个位置,以此类推。
列表的通用操作
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17my_list = [1, 2, 3] + [4, 5, 6]
print(len(my_list)) # 6
my_list = [1, 2, 3] * 5
print(len(my_list)) # 15
stus = ['孙悟空', '猪八戒', '沙和尚', '唐僧', '蜘蛛精', '白骨精', '沙和尚', '沙和尚']
print('牛魔王' in stus) # False
print('牛魔王' not in stus) # True
arr = [10, 1, 2, 5, 100, 77]
print(min(arr), max(arr)) # 1 100
print(stus.index('沙和尚')) # 2
print(stus.index('沙和尚', 3, 7)) # 6
# print(stus.index('牛魔王')) # ValueError: '牛魔王' is not in list
print(stus.count('牛魔王')) # 0列表的切片操作
1
2
3
4
5
6
7
8
9stus = ['孙悟空', '猪八戒', '沙和尚', '唐僧', '蜘蛛精', '白骨精']
print(stus[1:]) # ['猪八戒', '沙和尚', '唐僧', '蜘蛛精', '白骨精']
print(stus[:3]) # ['孙悟空', '猪八戒', '沙和尚']
print(stus[:]) # ['孙悟空', '猪八戒', '沙和尚', '唐僧', '蜘蛛精', '白骨精']
print(stus) # ['孙悟空', '猪八戒', '沙和尚', '唐僧', '蜘蛛精', '白骨精']
print(stus[0:5:3]) # ['孙悟空', '唐僧']
# print(stus[::0]) # ValueError: slice step cannot be zero
print(stus[::-1]) # ['白骨精', '蜘蛛精', '唐僧', '沙和尚', '猪八戒', '孙悟空'],列表反转列表元素的修改
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38stus = ['孙悟空', '猪八戒', '沙和尚', '唐僧', '蜘蛛精', '白骨精']
# 通过索引来修改元素
stus[0] = 'sunwukong'
stus[2] = '哈哈'
print(stus) # ['sunwukong', '猪八戒', '哈哈', '唐僧', '蜘蛛精', '白骨精']
# 通过del来删除元素
del stus[2] # 删除索引为2的元素
print(stus) # ['sunwukong', '猪八戒', '唐僧', '蜘蛛精', '白骨精']
# 通过切片来修改列表
# 在给切片进行赋值时,只能使用序列
stus[0:2] = ['牛魔王', '红孩儿'] # 使用新的元素替换旧元素
print(stus) # ['牛魔王', '红孩儿', '唐僧', '蜘蛛精', '白骨精']
stus[0:2] = ['牛魔王', '红孩儿', '二郎神', "sda"] # 新元素的个数可以超过旧元素
print(stus) # ['牛魔王', '红孩儿', '二郎神', 'sda', '唐僧', '蜘蛛精', '白骨精']
stus[0:0] = ['牛魔王'] # 向索引为0的位置插入元素
print(stus) # ['牛魔王', '牛魔王', '红孩儿', '二郎神', 'sda', '唐僧', '蜘蛛精', '白骨精']
# 当设置了步长时,序列中元素的个数必须和切片中元素的个数一致
print(stus[::2]) # ['牛魔王', '红孩儿', 'sda', '蜘蛛精'],指定步长,切片中元素个数为4
# stus[::2] = ['牛魔王', '红孩儿', '二郎神'] # 报错,序列中元素只有3个,ValueError: attempt to assign sequence of size 3 to extended slice of size 4
# 通过切片来删除元素
del stus[0:2] # 删除头两个元素
print(stus) # ['红孩儿', '二郎神', 'sda', '唐僧', '蜘蛛精', '白骨精']
del stus[::2] # 隔一个删一个
print(stus) # ['二郎神', '唐僧', '白骨精']
stus[1:3] = [] # 修改位置1和2的元素为空
print(stus) # ['二郎神']
# 以上操作,只适用于可变序列
s = 'hello'
# s[1] = 'a' # 不可变序列,无法通过索引来修改
# 可以通过list()函数将其他的序列转换为list
s = list(s)
print(s) # ['h', 'e', 'l', 'l', 'o']列表的方法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57stus = ['孙悟空', '猪八戒', '沙和尚', '唐僧']
# append()
# 向列表的最后添加一个元素
stus.append('唐僧1')
print(stus) # ['孙悟空', '猪八戒', '沙和尚', '唐僧', '唐僧1']
# insert()
# 向列表的指定位置插入一个元素
# 参数:
# 1.要插入的位置
# 2.要插入的元素
stus.insert(2, '唐僧2')
print(stus) # ['孙悟空', '猪八戒', '唐僧2', '沙和尚', '唐僧', '唐僧1']
# extend()
# 使用新的序列来扩展当前序列
# 需要一个序列作为参数,它会将该序列中的元素添加到当前列表中
stus.extend(['唐僧3', '白骨精']) # 等同于:stus += ['唐僧3','白骨精']
print(stus) # ['孙悟空', '猪八戒', '唐僧2', '沙和尚', '唐僧', '唐僧1', '唐僧3', '白骨精']
# pop()
# 根据索引删除并返回被删除的元素
result = stus.pop(2)
print(result) # 唐僧2
print(stus) # ['孙悟空', '猪八戒', '沙和尚', '唐僧', '唐僧1', '唐僧3', '白骨精']
result = stus.pop() # 删除最后一个元素
print(result) # 白骨精
print(stus) # ['孙悟空', '猪八戒', '沙和尚', '唐僧', '唐僧1', '唐僧3']
# remove()
# 删除指定值的元素,如果相同值的元素有多个,只会删除第一个
stus.remove('猪八戒')
print(stus) # ['孙悟空', '沙和尚', '唐僧', '唐僧1', '唐僧3']
# reverse()
# 用来反转列表
stus.reverse()
print(stus) # ['唐僧3', '唐僧1', '唐僧', '沙和尚', '孙悟空']
# clear()
# 清空序列
stus.clear()
print(stus) # []
# sort()
# 用来对列表中的元素进行排序,默认是升序排列
# 如果需要降序排列,则需要传递一个reverse=True作为参数
my_list = list('asnbdnbasdabd')
my_list.sort()
print(my_list) # ['a', 'a', 'a', 'b', 'b', 'b', 'd', 'd', 'd', 'n', 'n', 's', 's']
my_list = [10, 1, 20, 3, 4, 5, 0, -2]
my_list.sort()
print(my_list) # 升序:[-2, 0, 1, 3, 4, 5, 10, 20]
my_list.sort(reverse=True)
print(my_list) # 降序:[20, 10, 5, 4, 3, 1, 0, -2]列表的遍历
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25# 遍历列表,指的就是将列表中的所有元素取出来
# 创建列表
stus = ['孙悟空', '猪八戒', '沙和尚', '唐僧', '白骨精', '蜘蛛精']
# 遍历列表
# print(stus[0])
# print(stus[1])
# print(stus[2])
# print(stus[3])
# 通过while循环来遍历列表
i = 0
while i < len(stus):
print(stus[i])
i += 1
# 通过for循环来遍历列表
# 语法:
# for 变量 in 序列 :
# 代码块
# for循环的代码块会执行多次,序列中有几个元素就会执行几次
# 每执行一次就会将序列中的一个元素赋值给变量,
# 所以我们可以通过变量,来获取列表中的元素
for s in stus:
print(s)
元组(tuple)
1 | my_tuple = () # 创建了一个空元组 |
- 元组是一个不可变的序列,它的操作的方式基本上和列表是一致的。在操作元组时,可以把元组当成是一个不可变的列表。
- 一般当我们希望数据不改变时,就使用元组,其余情况都使用列表。
- 使用
()来创建元组。 - 元组是不可变对象,不能尝试为元组中的元素重新赋值。
- 当元组不是空元组时,括号可以省略。如果元组不是空元组,它里边至少要有一个
,。 - 元组的解包(解构):指的是将元组当中每一个元素都赋值给一个变量。利用元组的解包特性,可以直接交换 a 和 b 的值。说明:不光是元组,列表和字符串都能解包。
- 在对一个元组进行解包时,变量的数量必须和元组中的元素的数量一致。也可以在变量前边添加一个
*,这样该变量将会获取元组中所有剩余的元素,但不能同时出现两个或以上的带*变量。
可变对象说明
1 | # 列表是可变对象 |
每个对象中都保存了三个数据:id(标识),type(类型)和 value(值)。
列表就是一个可变对象,比如
a = [1, 2, 3]。a[0] = 10:改对象。- 这个操作是在通过变量去修改对象的值。
- 这种操作不会改变变量所指向的对象。
- 当我们去修改对象时,如果有其他变量也指向了该对象,则修改也会在其他的变量中体现。
a = [4, 5, 6]:改变量。- 这个操作是在给变量重新赋值。
- 这种操作会改变变量所指向的对象。
- 为一个变量重新赋值时,不会影响其他的变量。
一般只有在为变量赋值时才是修改变量,其余的都是修改对象。
比较符
1 | a = [1, 2, 3] |
==和!=比较的是对象的值是否相等。is和is not比较的是对象的 id 是否相等(比较两个对象是否是同一个对象)。
字典(dict)
1 | d = {} # 创建了一个空字典 |
字典属于一种新的数据结构,称为映射(mapping)。
字典的作用和列表类似,都是用来存储对象的容器。
列表存储数据的性能很好,但是查询数据的性能的很差。
在字典中每一个元素都有一个唯一的名字,通过这个唯一的名字可以快速的查找到指定的元素。
在查询元素时,字典的效率是非常快的。
在字典中可以保存多个对象,每个对象都会有一个唯一的名字。
- 这个唯一的名字,我们称其为键(key),通过 key 可以快速的查询 value。
- 这个对象,我们称其为值(value)。
- 所以字典,我们也称为键值对(key - value)结构。
- 每个字典中都可以有多个键值对,而每一个键值对我们称其为一项(item)。
使用
{}来创建字典。- 创建一个包含有数据的字典:
{key: value, key: value, key: value}。 - 字典的键可以是任意的不可变对象(int、str、bool、tuple …),但是一般我们都会使用 str。
- 字典的值可以是任意对象。
- 字典的键是不能重复的,如果出现重复,后边的会替换前边的。
- 创建一个包含有数据的字典:
字典的使用
1 | # 创建字典 |
字典的遍历
1 | d = {'name': '孙悟空', 'age': 18, 'gender': '男'} |
集合(set)
- 集合和列表非常相似。
- 不同点:
- 集合中只能存储不可变对象。
- 集合中存储的对象是无序(不是按照元素的插入顺序保存)。
- 集合中不能出现重复的元素。
集合的使用
1 | # 集合的创建 |
集合的运算
1 | # 在对集合做运算时,不会影响原来的集合,而是返回一个运算结果 |
函数(function)
函数简介
1 | # 定义一个函数 |
函数也是一个对象,对象是内存中专门用来存储数据的一块区域。
函数可以用来保存一些可执行的代码,并且可以在需要时,对这些语句进行多次的调用。
创建函数:
1
2def 函数名([形参1, 形参2, ... 形参n]):
代码块- 函数名必须要符号标识符的规范(可以包含字母、数字、下划线,但是不能以数字开头)。
- 函数中保存的代码不会立即执行,需要调用函数代码才会执行。
调用函数:
1
函数对象()
定义函数一般都是要实现某种功能的。
函数的参数
1 | # 求任意三个数的乘积 |
- 在定义函数时,可以在函数名后的
()中定义数量不等的形参,多个形参之间使用,隔开。 - 形参(形式参数),定义形参就相当于在函数内部声明了变量,但是并不赋值。
- 实参(实际参数)。
- 如果函数定义时,指定了形参,那么在调用函数时也必须传递实参, 实参将会赋值给对应的形参,简单来说,有几个形参就得传几个实参。
参数的传递方式
1 | # 定义函数,并为形参指定默认值 |
- 定义形参时,可以为形参指定默认值。指定了默认值以后,如果用户传递了参数,则默认值没有任何作用;如果用户没有传递参数,则默认值就会生效。
- 位置参数:即将对应位置的实参复制给对应位置的形参。
- 关键字参数:可以不按照形参定义的顺序去传递,而直接根据参数名去传递参数。
- 位置参数和关键字参数可以混合使用,混合使用时,必须将位置参数写到前面。
- 函数在调用时,解析器不会检查实参的类型,实参可以传递任意类型的对象。
- 在函数中对形参进行重新赋值,不会影响其他的变量。
- 如果形参指向的是一个对象,当我们通过形参去修改对象时,会影响到所有指向该对象的变量。
不定长的参数
1 | # 定义一个函数,可以求任意个数字的和 |
- 在定义函数时,可以在形参前边加上一个
*,这样这个形参将会获取到所有的实参,并将所有的实参保存到一个元组中。 - 带
*的形参只能有一个。 - 带
*的参数,可以和其他参数配合使用。 - 可变参数不是必须写在最后,但是注意,带
*的参数后的所有参数,必须以关键字参数的形式传递,否则报错。 - 如果在形参的开头直接写一个
*,则要求所有的参数必须以关键字参数的形式传递。 *形参只能接收位置参数,而不能接收关键字参数。**形参可以接收其他的关键字参数,它会将这些参数统一保存到一个字典中。字典的 key 就是参数的名字,字典的 value 就是参数的值。**形参只能有一个,并且必须写在所有参数的最后。- 传递实参时,也可以在序列类型的参数前添加
*,这样会自动将序列中的元素依次作为参数传递给函数,但要求序列中元素的个数必须和形参的个数一致。 - 如果是字典,通过
**来进行解包操作。
函数的返回值
1 | # return 后边跟什么值,函数就会返回什么值 |
- 返回值就是函数执行以后返回的结果,可以通过
return来指定函数的返回值。 return后边可以跟任意的对象,甚至可以是一个函数。return后边跟什么值,函数就会返回什么值。- 如果仅仅写一个
return或者不写return,则相当于return None。 - 在函数中,
return后的代码都不会执行,return一旦执行函数自动结束。
文档字符串
1 | # help()是Python中的内置函数 |
作用域
1 | # 作用域(scope) |
命名空间
1 | # 命名空间(namespace) |
递归
1 | # 10的阶乘 |
高阶函数
1 | # 高阶函数 |
在 Python 中,函数是一等对象。一等对象一般都会具有如下特点:
- 对象是在运行时创建的。
- 能赋值给变量或作为数据结构中的元素。
- 能作为参数传递。
- 能作为返回值返回。
高阶函数至少要符合以下两个特点中的一个:
- 能接收一个或多个函数作为参数。
- 能将函数作为返回值返回。
当我们使用一个函数作为参数时,实际上是将指定的代码传递进了目标函数。
匿名函数
匿名函数是将一个或多个函数作为参数来接收。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69# fn1~fn3是作为参数传递进filter()函数中
# 而fn1~fn3实际上只有一个作用,就是作为filter()的参数
# filter()调用完毕以后,fn1~fn3就已经没用
# 这种情况可以用匿名函数简化
# 匿名函数lambda函数表达式(语法糖)
# lambda函数表达式专门用来创建一些简单的函数,他是函数创建的又一种方式
# 语法:lambda 参数列表 : 返回值
# 匿名函数一般都是作为参数使用,其他地方一般不会使用
# 待提取列表
l = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
# 常规写法
def fn5(a, b):
return a + b
print(fn5(10, 20)) # 常规写法
print((lambda a, b: a + b)(10, 20)) # lambad表达式写法
fn6 = lambda a, b: a + b # 也可以将匿名函数赋值给一个变量,一般不会这么做
print(fn6(10, 20))
# filter()函数中可以很方便的使用lambda表达式
# 此时,lambda表达式只会使用一次,使用完后内存中自动回收
r = filter(lambda i: i % 2 == 0, l)
print(list(r)) # [2, 4, 6, 8, 10]
print(list(filter(lambda i: i > 5, l))) # [6, 7, 8, 9, 10]
# map()函数可以对可迭代对象中的所有元素做指定的操作,然后将其添加到一个新的对象中返回
print(list(map(lambda i: i ** 2, l))) # 对列表中的每一个元素求平方,[1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
# sort()函数用来对列表中的元素进行排序:
# sotr()只能排序列表
# 默认是直接比较列表中的元素的大小
# 在sort()可以接收一个关键字参数key:
# key需要一个函数作为参数,当设置了函数作为参数
# 每次都会以列表中的一个元素作为参数来调用该函数
# 并且使用函数的返回值来比较元素的大小
l = ['bb', 'aaaa', 'c', 'ddddddddd', 'fff']
l.sort()
print(l) # 默认比较:['aaaa', 'bb', 'c', 'ddddddddd', 'fff']
l = ['bb', 'aaaa', 'c', 'ddddddddd', 'fff']
l.sort(key=len)
print(l) # 按长度比较:['c', 'bb', 'fff', 'aaaa', 'ddddddddd']
l = [2, 5, '1', 3, '6', '4']
l.sort(key=int)
print(l) # 把每一个元素转换成整形后再比较:['1', 2, 3, '4', 5, '6']
l = [2, 5, '1', 3, '6', '4']
l.sort(key=str)
print(l) # 把每一个元素转换成字符串后再比较:['1', 2, 3, '4', 5, '6']
# sorted()函数和sort()的用法基本一致,但是sorted()可以对任意的序列进行排序
# 并且使用sorted()排序不会影响原来的对象,而是返回一个新对象
l = [2, 5, '1', 3, '6', '4'] # 排序列表
print('排序前:', l) # 排序前: [2, 5, '1', 3, '6', '4']
print('排序中:', sorted(l, key=int)) # 排序中: ['1', 2, 3, '4', 5, '6']
print('排序后:', l) # 排序后: [2, 5, '1', 3, '6', '4']
l = '123765816742634781' # 排序字符串
print('排序前:', l) # 排序前: 123765816742634781
print('排序中:', sorted(l,
key=int)) # 排序中: ['1', '1', '1', '2', '2', '3', '3', '4', '4', '5', '6', '6', '6', '7', '7', '7', '8', '8']
print('排序后:', l) # 排序后: 123765816742634781
闭包
闭包是将函数作为返回值返回。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56# 将函数作为返回值返回,也是一种高阶函数
# 这种高阶函数我们也称为叫做闭包,通过闭包可以创建一些只有当前函数能访问的变量
# 可以将一些私有的数据藏到闭包中
def fn():
a = 10
# 函数内部再定义一个函数
def inner():
print('我是fn2', a)
# 将内部函数 inner作为返回值返回
return inner
# r是一个函数,是调用fn()后返回的函数
# 而且这个函数是在fn()内部定义,并不是全局函数
# 所以这个函数总是能访问到fn()函数内的变量
r = fn()
print(r) # <function fn.<locals>.inner at 0x000001CEC1142430>
r() # 我是fn2 10
# 求多个数的平均值
nums = [50, 30, 20, 10, 77]
# 常规写法:sum()用来求一个列表中所有元素的和
print(sum(nums) / len(nums)) # 37.4
# 如果nums中的数据是变化的,可以使用闭包
# 形成闭包的要件
# ① 函数嵌套
# ② 将内部函数作为返回值返回
# ③ 内部函数必须要使用到外部函数的变量
def make_averager():
# 创建一个列表,用来保存数值
nums = []
# 创建一个函数,用来计算平均值
def averager(n):
# 将n添加到列表中
nums.append(n)
# 求平均值
return sum(nums) / len(nums)
return averager
# 函数返回的是make_averager()中定义的averager()函数
# 并创建了一个nums列表,这个列表外界无法访问,只有averager对象可以访问
averager = make_averager()
print(averager(10)) # 10/1=10
print(averager(20)) # (10+20)/2=15
print(averager(30)) # (10+20+30)/3=20
print(averager(40)) # (10+20+30+40)/4=25
装饰器
1 | # 创建几个函数 |
对象(object)
什么是对象
- 对象是内存中专门用来存储数据的一块区域。
- 对象中可以存放各种数据,比如:数字、布尔值、代码。
- 对象由三部分组成:
- 对象的标识(id)
- 对象的类型(type)
- 对象的值(value)
面向对象(oop)
Python 是一门面向对象的编程语言。
所谓的面向对象的语言,简单理解就是语言中的所有操作都是通过对象来进行的。
面向过程的编程的语言:
- 面向过程指将我们的程序的逻辑分解为一个一个的步骤,通过对每个步骤的抽象,来完成程序。
- 例子:孩子上学,可能有以下过程。
- 妈妈起床。
- 妈妈洗漱。
- 妈妈做早饭。
- 妈妈叫孩子起床。
- 孩子要洗漱。
- 孩子吃饭。
- 孩子背着书包上学校。
- 面向过程的编程思想将一个功能分解为一个一个小的步骤,我们通过完成一个一个的小的步骤来完成一个程序。
- 这种编程方式,符合我们人类的思维,编写起来相对比较简单。
- 但是这种方式编写代码的往往只适用于一个功能,如果要在实现别的功能,即使功能相差极小,也往往要重新编写代码,所以它可复用性比较低,并且难于维护 。
面向对象的编程语言:
- 面向对象的编程语言,关注的是对象,而不关注过程。
- 对于面向对象的语言来说,一切都是对象。
- 面向对象的编程思想,将所有的功能统一保存到对应的对象中。比如,妈妈的功能保存到妈妈的对象中,孩子的功能保存到孩子对象中,要使用某个功能,直接找到对应的对象即可。
- 这种方式编写的代码,比较容易阅读,并且比较易于维护,容易复用。
- 但是这种方式编写,不太符合常规的思维,编写起来稍微麻烦一点。
简单归纳一下,面向对象的思想:
- 第一步:创建对象。
- 第二步:处理对象。
类的简介
1 | a = int(10) # 创建一个int类的实例 |
我们目前所学习的对象都是 Python 内置的对象。
但是内置对象并不能满足所有的需求,所以我们在开发中经常需要自定义一些对象。
类,简单理解它就相当于一个图纸。在程序中我们需要根据类来创建对象。
类就是对象的图纸!
我们也称对象是类的实例(instance)。
如果多个对象是通过一个类创建的,我们称这些对象是一类对象。
像
int(),float(),bool(),str(),list(),dict()等,这些都是类。a = int(10) # 创建一个int类的实例等价于a = 10。我们自定义的类都需要使用大写字母开头,使用大驼峰命名法(帕斯卡命名法)来对类命名。
类也是一个对象!
类就是一个用来创建对象的对象!
类是 type 类型的对象,定义类实际上就是定义了一个 type 类型的对象。
使用类创建对象的流程:
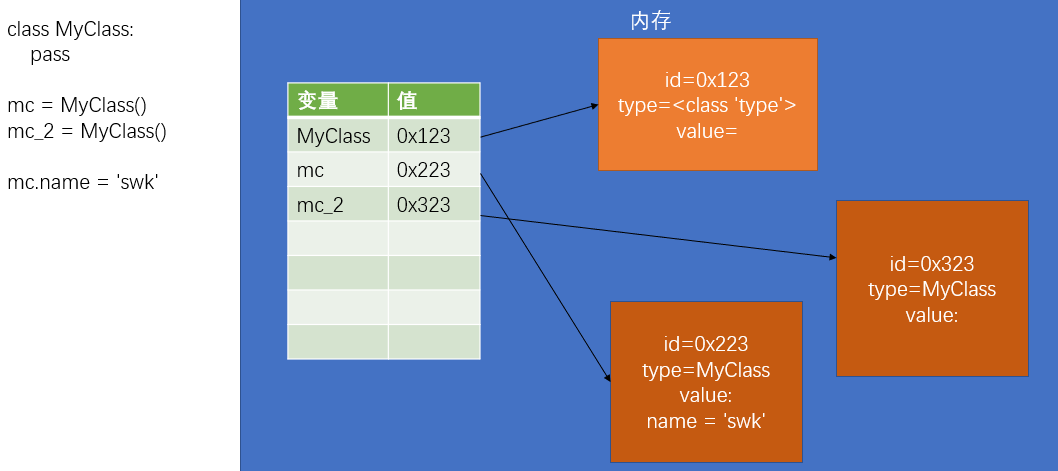
- 第一步:创建一个变量。
- 第二步:在内存中创建一个新对象。
- 第三步:将对象的 id 赋值给变量。
类的定义
1 | # 尝试定义一个表示人的类 |
- 类和对象都是对现实生活中的事物或程序中的内容的抽象。
- 实际上所有的事物都由两部分构成:
- 数据(属性)
- 行为(方法)
- 在类的代码块中,我们可以定义变量和函数:
- 变量会成为该类实例的公共属性,所有的该类实例都可以通过
对象.属性名的形式访问。 - 函数会成为该类实例的公共方法,所有该类实例都可以通过
对象.方法名()的形式调用方法。
- 变量会成为该类实例的公共属性,所有的该类实例都可以通过
- 注意:方法调用时,默认第一个参数由解析器自动传递,所以定义方法时,至少要定义一个形参!
- 实例为什么能访问到类中的属性和方法:
- 类中定义的属性和方法都是公共的,任何该类实例都可以访问。
- 属性和方法查找的流程:
- 当我们调用一个对象的属性时,解析器会先在当前对象中寻找是否含有该属性,如果有,则直接返回当前的对象的属性值;如果没有,则去当前对象的类对象中去寻找,如果有,则返回类对象的属性值,如果类对象中依然没有,则报错!
- 类对象和实例对象中都可以保存属性(方法):
- 如果这个属性(方法)是所有的实例共享的,则应该将其保存到类对象中。
- 如果这个属性(方法)是某个实例独有,则应该保存到实例对象中。
- 比如,Person 类中,name 属性每个对象都不同,应该保存到各个实例对象中,而国籍假设都是中国人,是一样的,则应该保存到类对象中。
- 一般情况下,属性保存到实例对象中,而方法需要保存到类对象中。
对象的初始化
1 | class Person: |
1 | class Dog: |
类的基本结构:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16class 类名([父类]) :
公共的属性...
# 对象的初始化方法
def __init__(self,...):
...
# 其他的方法
def method_1(self,...):
...
def method_2(self,...):
...
...创建对象的流程,
p1 = Person():- 第一步:创建一个变量。
- 第二步:在内存中创建一个新对象。
- 第三步:
__init__(self)方法执行。 - 第四步:将对象的 id 赋值给变量。
封装
1 | # 封装是面向对象的三大特性之一 |
1 | class Rectangle: |
1 | class Person: |
继承
1 | # 继承 |
1 | class Animal: |
重写
1 | # 继承 |
多重继承
1 | class A(object): |
多态
1 | # 多态是面向对象的三大特征之一 |
类中的属性和方法
1 | # 定义一个类 |
垃圾回收
1 | # 就像我们生活中会产生垃圾一样,程序在运行过程当中也会产生垃圾 |
特殊方法
1 | # 特殊方法,也称为魔术方法 |
模块化
简介:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26# 模块(module)
# 模块化,模块化指将一个完整的程序分解为一个一个小的模块
# 通过将模块组合,来搭建出一个完整的程序
# 不采用模块化:统一将所有的代码编写到一个文件中
# 采用模块化:将程序分别编写到多个文件中
# 模块化的优点:
# ① 方便开发
# ② 方便维护
# ③ 模块可以复用!
# 在Python中一个py文件就是一个模块,要想创建模块,实际上就是创建一个python文件
# 注意:模块名要符号标识符的规范
# 在一个模块中引入外部模块:
# ① import 模块名 (模块名,就是python文件的名字,注意不要.py后缀)
# ② import 模块名 as 模块别名
# - 可以引入同一个模块多次,但是模块的实例只会创建一个
# - import可以在程序的任意位置调用,但是一般情况下,import语句都会统一写在程序的开头
# - 在每一个模块内部都有一个__name__属性,通过这个属性可以获取到模块的名字
# - __name__属性值为 __main__的模块是主模块,一个程序中只会有一个主模块
# 主模块就是我们直接通过 python 执行的模块(当前程序所在的模块)
import test_module as test
print(__name__) # 主模块:__main__
print(test.__name__) # 引入的外部模块:test_modulem.py:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32# 可以在模块中定义变量,在模块中定义的变量,在引入该模块后,就可以直接使用了
a = 10
b = 20
# 添加了_的变量,只能在模块内部访问,在通过 import * 方式引入时,不会引入_开头的变量
_c = 30
# 可以在模块中定义函数,同样可以通过模块访问到
def test():
print('test')
def test2():
print('test2')
# 也可以定义类
class Person:
def __init__(self):
self.name = '孙悟空'
# 编写测试代码:
# 这部分代码,只有当前模块作为主模块的时候才需要被执行
# 而当前模块被其他模块引入时,不需要被执行
# 此时,我们就必须要检查当前模块是否是主模块
if __name__ == '__main__':
test()
test2()
p = Person()
print(p.name)main.py:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55import m
# 访问模块中的变量:模块名.变量名
print(m.a, m.b) # 10 20.
# print(m._c) # 此方式可以访问_c属性
# 访问模块中的方法:模块名.方法名
m.test() # test
m.test2() # test2
# 访问模块中的类:模块名.类名,创建类的实例
p = m.Person()
print(p.name) # 孙悟空
# 也可以只引入模块中的部分内容
# 语法: from 模块名 import 变量, 变量....
# from m import Person # 只引入Person
# from m import test # 只引入test
from m import Person, test # 引入多个
# 通过上面方式引入后,可以直接使用
p1 = Person()
print(p1) # <m.Person object at 0x00000115DD088160>
test() # test
# test2() # test2()没有引入,不能直接使用
# from m import * # 引入模块中所有内容,一般不会使用
# 当前模块中,会覆盖被引入模块中的同名方法
def test2():
print('这是主模块中的test2')
test2() # 这是主模块中的test2
# 也可以为引入的变量使用别名
# 语法:from 模块名 import 变量 as 别名
from m import test2 as new_test2
test2() # 这是主模块中的test2
new_test2() # test2
# from m import *
# print(_c) # _c属性无法访问
# 总结:
# import xxx
# import xxx as yyy
# from xxx import yyy , zzz , fff
# from xxx import *
# from xxx import yyy as zz
包
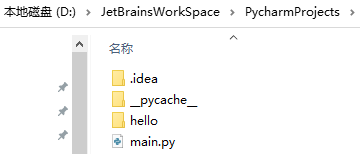
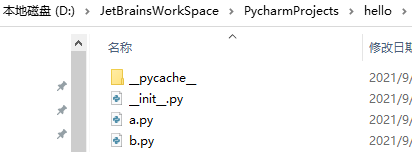
结构:
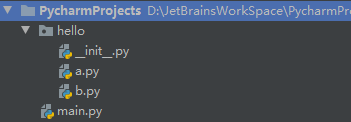
hello/__init__.py:1
2def test():
print('test')hello/a.py:1
c = 30
hello/b.py:1
d = 40
main.py:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15# 包 Package
# 包也是一个模块
# 当我们模块中代码过多时,或者一个模块需要被分解为多个模块时,这时就需要使用到包
# 普通的模块就是一个py文件,而包是一个文件夹
# 包中必须要有一个 __init__.py 文件,这个文件中可以包含有包中的主要内容
from hello import a, b
print(a.c)
print(b.d)
# __pycache__ 是模块的缓存文件
# .py代码在执行前,需要被解析器先转换为机器码,然后再执行
# 所以我们在使用模块(包)时,也需要将模块的代码先转换为机器码,然后再交由计算机执行
# 而为了提高程序运行的性能,python会在编译过一次以后,将代码保存到一个缓存文件中
# 这样在下次加载这个模块(包)时,就可以不再重新编译而是直接加载缓存中编译好的代码即可
Python 标准库
1 | # 思想:开箱即用 |
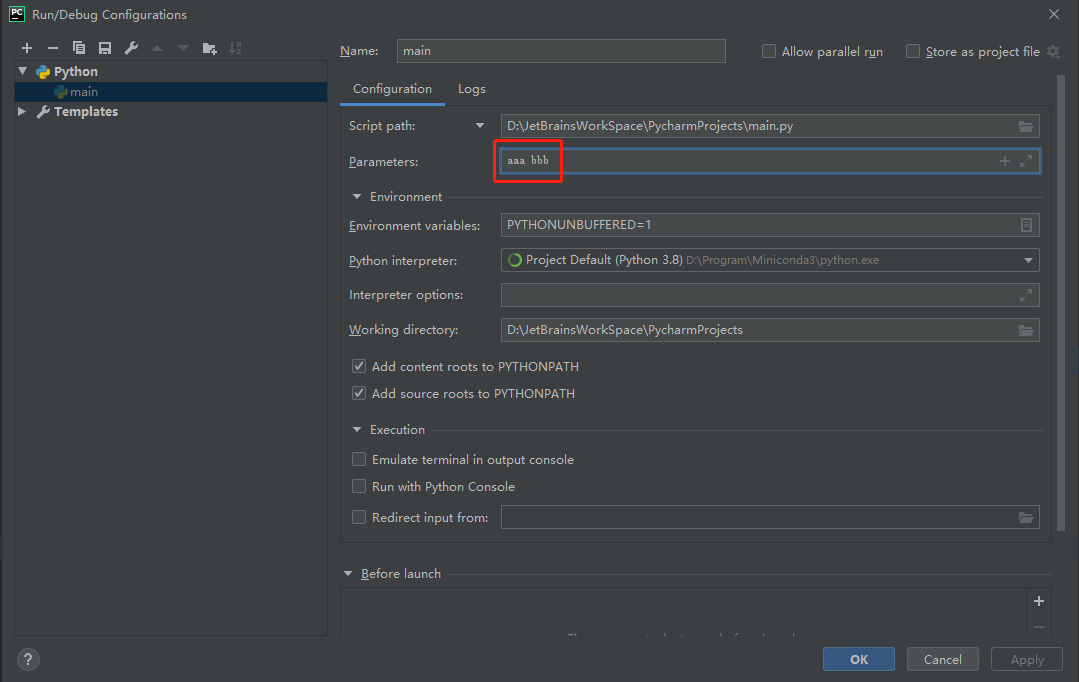
命令行执行代码时的参数:
2
['main.py', 'aaa', 'bbb']
异常和文件
异常
- 程序在运行过程当中,不可避免的会出现一些错误,比如:使用了没有赋值过的变量,使用了不存在的索引,除 0 等。这些错误在程序中,我们称其为异常。
- 程序运行过程中,一旦出现异常将会导致程序立即终止,异常以后的代码全部都不会执行!
处理异常
程序运行时出现异常,目的并不是让我们的程序直接终止!Python 是希望在出现异常时,我们可以编写代码来对异常进行处理!
try 语句:
1
2
3
4
5
6
7
8
9
10
11
12try:
代码块(可能出现错误的语句)
except 异常类型 as 异常名:
代码块(出现错误以后的处理方式)
except 异常类型 as 异常名:
代码块(出现错误以后的处理方式)
except 异常类型 as 异常名:
代码块(出现错误以后的处理方式)
else:
代码块(没出错时要执行的语句)
finally:
代码块(该代码块总会执行)try 是必须的,else 语句有没有都行,except 和 finally 至少有一个。
可以将可能出错的代码放入到 try 语句,这样如果代码没有错误,则会正常执行,如果出现错误,则会执行 expect 子句中的代码,这样我们就可以通过代码来处理异常,避免因为一个异常导致整个程序的终止。
异常的传播
1 | def fn(): |
- 当在函数中出现异常时,如果在函数中对异常进行了处理,则异常不会再继续传播,如果函数中没有对异常进行处理,则异常会继续向函数调用处传播,如果函数调用处处理了异常,则不再传播,如果没有处理则继续向调用处传播,直到传递到全局作用域(主模块),如果依然没有处理,则程序终止,并且显示异常信息。
- 当程序运行过程中出现异常以后,所有的异常信息会被保存一个专门的异常对象中,而异常传播时,实际上就是异常对象抛给了调用处。比如:
- ZeroDivisionError 类的对象专门用来表示除 0 的异常。
- NameError 类的对象专门用来处理变量错误的异常。
- 在 Python 为我们提供了多个异常对象。
异常对象
1 | print('异常出现前') |
抛出异常
1 | # 也可以自定义异常类,只需要创建一个类继承Exception即可 |
- 可以使用 raise 语句来抛出异常,raise 语句后需要跟一个异常类或异常的实例。
文件
- 通过 Python 程序来对计算机中的各种文件进行增删改查的操作。
- 操作文件的步骤:
- 打开文件。
- 对文件进行各种操作(读、写),然后保存。
- 关闭文件。
打开文件
1 | # open(file, mode='r', buffering=-1, encoding_=None, errors=None, newline=None, closefd=True, opener=None) |
关闭文件
1 | # 打开文件 |
读取文件
1 | file_name = 'demo.txt' |
1 | import pprint |
写入文件
1 | file_name = 'demo1.txt' |
二进制文件操作
1 | file_name = 'F:/QQMusic/FLOW - Go!!!.flac' |
seek() 和 tell()
1 | # 二进制文件 |
文件的其他操作
1 | import os |
本文参考
https://www.liaoxuefeng.com/wiki/1016959663602400
声明:写作本文初衷是个人学习记录,鉴于本人学识有限,如有侵权或不当之处,请联系 wdshfut@163.com。