Kafka 的 consumer 比 producer 要复杂许多,producer 没有 group 的概念,也不需要关注 offset,而 consumer 不一样,它有组织 (consumer group),有纪律 (offset)。这些对 consumer 的要求就会很高,这篇文章就主要介绍 consumer 是如何加入 consumer group 的。
在这之前,我们需要先了解一下什么是 GroupCoordinator。简单地说,GroupCoordinator 是运行在服务器上的一个服务,Kafka 集群上的每一个 broker 节点启动的时候,都会启动一个 GroupCoordinator 服务,其功能是负责进行 consumer 的 group 成员与 offset 管理 (但每个 GroupCoordinator 只是管理一部分的 consumer group member 和 offset 信息)。
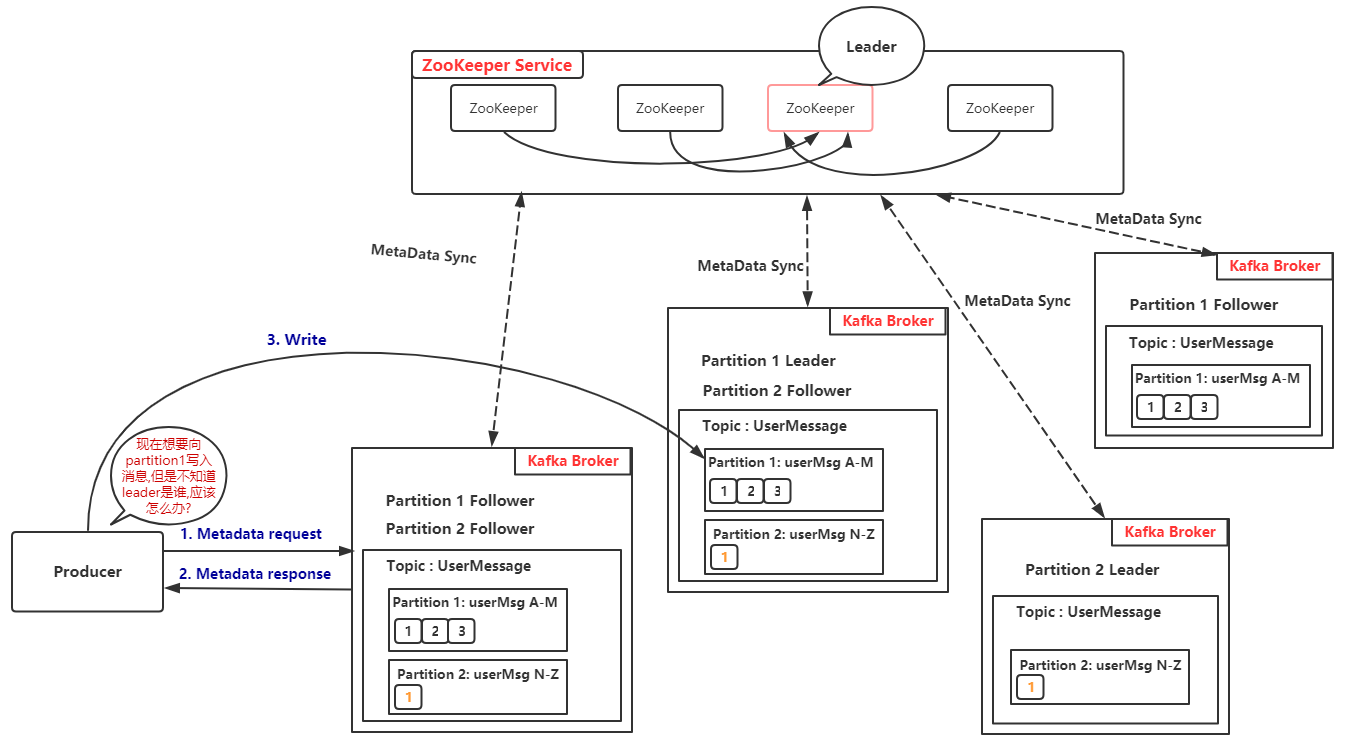
consumer group 对应的 GroupCoordinator 节点的确定,会通过如下方式:
将 consumer group 的 group.id 进行 hash,把得到的值的绝对值,对 _consumer_offsets 的 partition 总数取余,然后得到其对应的 partition 值,该 partition 的 leader 所在的 broker 即为该 consumer group 所对应的 GroupCoordinator 节点,GroupCoordinator 会存储与该 consumer group 相关的所有的 Meta 信息。
1._consumer_offsets 这个 topic 是 Kafka 内部使用的一个 topic,专门用来存储 group 消费的情况,默认情况下有 50 个 partition,每个 partition 默认有三个副本。
2.partition 计算方式:
abs(GroupId.hashCode()) % NumPartitions,其中,NumPartitions 是 _consumer_offsets 的 partition 数,默认是 50 个。3.比如,现在通过计算
abs(GroupId.hashCode()) % NumPartitions的值为 35,然后就找第 35 个 partition 的 leader 在哪个 broker 上 (假设在 192.168.1.12),那么 GroupCoordinator 节点就在这个 broker 上。
同时,这个 consumer group 所提交的消费 offset 信息也会发送给这个 partition 的 leader 所对应的 broker 节点,因此,这个节点不仅是 GroupCoordinator,而且还保存分区分配方案和组内消费者 offset 信息。
更多关于 GroupCoordinator 的解析,参考:Kafka 源码解析之 GroupCoordinator 详解。
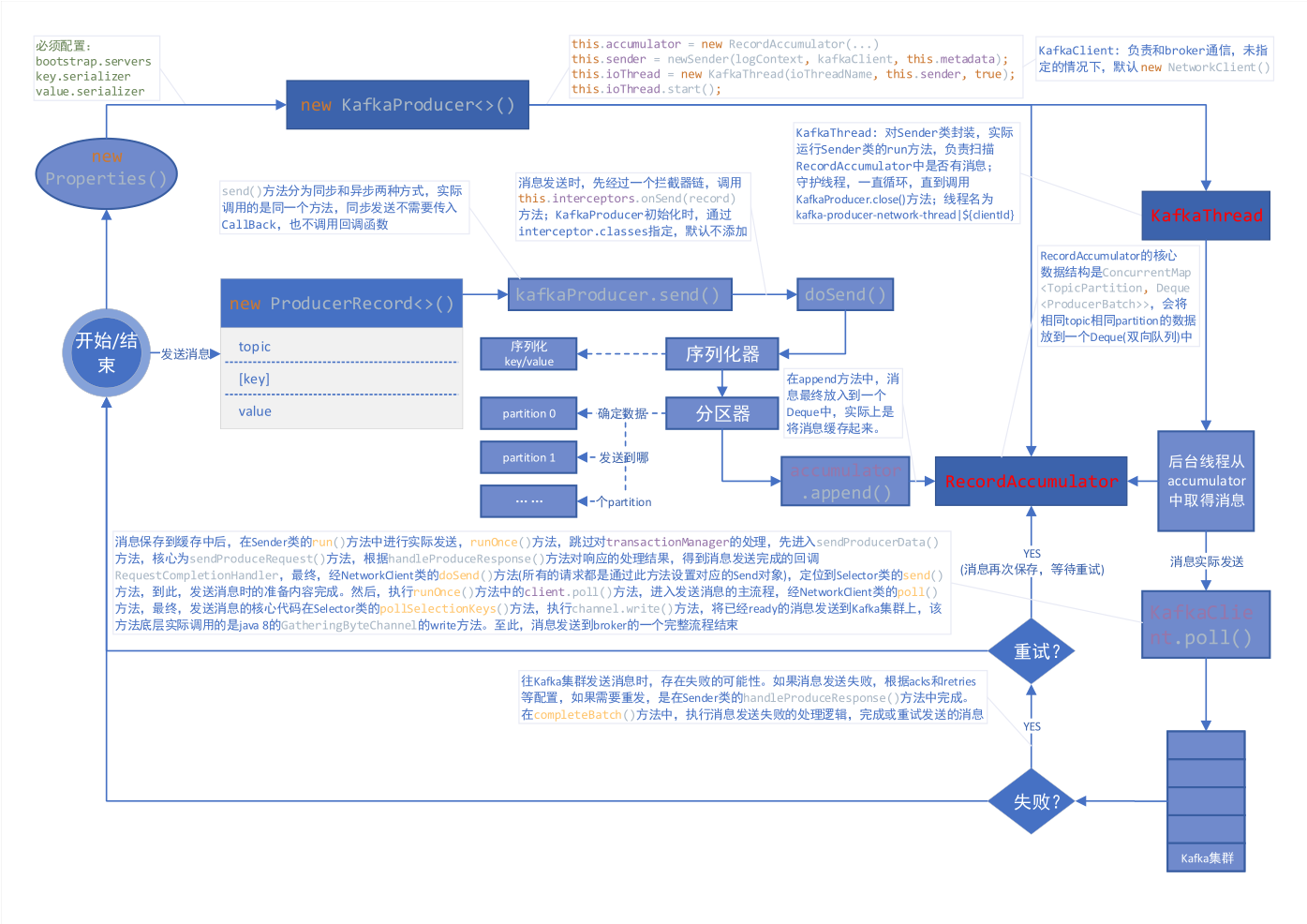
KafkaConsumer 消费消息的主体流程
接下来,我们回顾下 KafkaConsumer 消费消息的主体流程:
1 | // 创建消费者 |
创建 KafkaConsumer
创建 KafkaConsumer 的时候,会创建一个 ConsumerCoordinator 服务,由它来负责和 GroupCoordinator 通信:
1 | // no coordinator will be constructed for the default (null) group id |
订阅 topic
KafkaConsumer 订阅 topic 的方式有好几种,这在前面的文章有提到过。订阅的时候,会根据订阅的方式,设置其对应的订阅类型,默认存在四种订阅类型:
1 | private enum SubscriptionType { |
比如,采用 kafkaConsumer.subscribe(Collections.singletonList("consumerCodeTopic")) 方式订阅 topic 时,会将订阅类型设置为 SubscriptionType.AUTO_TOPICS,其核心代码如下:
1 | /** |
1 | /** |
1 | public synchronized boolean subscribe(Set<String> topics, ConsumerRebalanceListener listener) { |
1 | /** |
从服务器拉取数据
订阅完成后,就可以从服务器拉取数据了,应该注意的是,KafkaConsumer 没有后台线程默默的拉取数据,它的所有行为都集中在 poll () 方法中,KafkaConsumer 是线程不安全的,同时只能允许一个线程运行。
kafkaConsumer.poll () 方法的核心代码如下:
1 | private ConsumerRecords<K, V> poll(final Timer timer, final boolean includeMetadataInTimeout) { |
可以看出,在 Step 1 阶段, poll () 方法会先进行判定,如果有多个线程同时使用一个 KafkaConsumer 则会抛出异常:
1 | /** |
1 | /** |
KafkaConsumer 如何加入 consumer group
一个 KafkaConsumer 实例消费数据的前提是能够加入一个 consumer group 成功,并获取其要订阅的 tp(topic-partition)列表,因此首先要做的就是和 GroupCoordinator 建立连接,加入组织。
consumer 加入 group 的过程,也就是 reblance 的过程。如果出现了频繁 reblance 的问题,可能和
max.poll.interval.ms和max.poll.records两个参数有关。
因此,我们先把目光集中在 ConsumerCoordinator 上,这个过程主要发生在 Step 2 阶段:
1 | /** |
关于对 ConsumerCoordinator 的处理都集中在 coordinator.poll () 方法中。其主要逻辑如下:
1 | /** |
coordinator.poll () 方法中,具体实现可以分为四个步骤:
pollHeartbeat ():检测心跳线程运行是否正常,需要定时向 GroupCoordinator 发送心跳,如果超时未发送心跳,consumer 会离开 consumer group。ensureCoordinatorReady ():当通过subscribe ()方法订阅 topic 时,如果 coordinator 未知,则初始化 ConsumerCoordinator (在ensureCoordinatorReady ()中实现,该方法主要的作用是发送 FindCoordinatorRequest 请求,并建立连接)。ensureActiveGroup ():判断是否需要重新加入 group,如果订阅的 partition 变化或者分配的 partition 变化时,需要 rejoin,则通过ensureActiveGroup ()发送 join-group、sync-group 请求,加入 group 并获取其 assign 的 TopicPartition list。maybeAutoCommitOffsetsAsync ():如果设置的是自动 commit,并且达到了发送时限则自动 commit offset。
关于 rejoin,下列几种情况会触发再均衡 (reblance) 操作:
订阅的 topic 列表变化
topic 被创建或删除
新的消费者加入消费者组 (第一次进行消费也属于这种情况)
消费者宕机下线 (长时间未发送心跳包)
消费者主动退出消费组,比如调用
unsubscrible ()方法取消对主题的订阅消费者组对应的 GroupCoorinator 节点发生了变化
消费者组内所订阅的任一主题或者主题的分区数量发生了变化
取消 topic 订阅,consumer 心跳线程超时以及在 Server 端给定的时间内未收到心跳请求,这三个都是触发的 LEAVE_GROUP 请求。
下面重点介绍下第二步中的 ensureCoordinatorReady () 方法和第三步中的 ensureActiveGroup () 方法。
ensureCoordinatorReady
ensureCoordinatorReady ()这个方法主要作用:选择一个连接数最少的 broker (还未响应请求最少的 broker),发送 FindCoordinator 请求,找到 GroupCoordinator 后,建立对应的 TCP 连接。
- 方法调用流程是
ensureCoordinatorReady ()→lookupCoordinator ()→sendFindCoordinatorRequest ()。 - 如果 client 收到 server response,那么就与 GroupCoordinator 建立连接。
1 | /** |
1 | protected synchronized RequestFuture<Void> lookupCoordinator() { |
1 | /** |
1 | // 根据response返回的ip以及端口信息,和该broke上开启的GroupCoordinator建立连接 |
上面代码主要作用就是:往一个负载最小的 broker 节点发起 FindCoordinator 请求,Kafka 在走到这个请求后会根据 group_id 查找对应的 GroupCoordinator 节点 (文章开头处介绍的方法),如果找到对应的 GroupCoordinator 则会返回其对应的 node_id,host 和 port 信息,并建立连接。
这里的 GroupCoordinator 节点的确定在文章开头提到过,是通过
group.id和 partitionCount 来确定的。
ensureActiveGroup
现在已经知道了 GroupCoordinator 节点,并建立了连接。ensureActiveGroup () 这个方法的主要作用:向 GroupCoordinator 发送 join-group、sync-group 请求,获取 assign 的 tp list。
- 调用过程是
ensureActiveGroup ()→ensureCoordinatorReady ()→startHeartbeatThreadIfNeeded ()→joinGroupIfNeeded ()。 joinGroupIfNeeded ()方法中最重要的方法是initiateJoinGroup (),它的的调用流程是disableHeartbeatThread ()→sendJoinGroupRequest ()→JoinGroupResponseHandler::handle ()→onJoinLeader (),onJoinFollower ()→sendSyncGroupRequest ()。
1 | /** |
心跳线程就是在这里启动的,但是并不一定马上发送心跳包,会在满足条件之后才会开始发送。后面最主要的逻辑就集中在 joinGroupIfNeeded () 方法,它的核心代码如下:
1 | /** |
initiateJoinGroup () 方法的核心代码如下:
1 | private synchronized RequestFuture<ByteBuffer> initiateJoinGroup() { |
可以看到在 joinGroup 之前会让心跳线程暂时停下来,此时会将 ConsumerCoordinator 的状态设置为 rebalance 状态,当 joinGroup 成功之后会将状态设置为 stable 状态,同时让之前停下来的心跳线程继续运行。
sendJoinGroupRequest () 方法的核心代码如下:
1 | /** |
在发送 joinGroup 请求之后,会收到来自服务器的响应,然后针对这个响应再做一些重要的事情:
1 | // 处理发送joinGroup请求后的response的handler(同步group信息) |
上面代码的主要过程如下:
- 如果 group 是新的
group.id,那么此时 group 初始化的状态为 Empty; - 当 GroupCoordinator 接收到 consumer 的 join-group 请求后,由于此时这个 group 的 member 列表还是空 (group 是新建的,每个 consumer 实例被称为这个 group 的一个 member),第一个加入的 member 将被选为 leader,也就是说,对于一个新的 consumer group 而言,当第一个 consumer 实例加入后将会被选为 leader。如果后面 leader 挂了,会从其他 member 里面随机选择一个 member 成为新的 leader;
- 如果 GroupCoordinator 接收到 leader 发送 join-group 请求,将会触发 rebalance,group 的状态变为 PreparingRebalance;
- 此时,GroupCoordinator 将会等待一定的时间,如果在一定时间内,接收到 join-group 请求的 consumer 将被认为是依然存活的,此时 group 会变为 AwaitSync 状态,并且 GroupCoordinator 会向这个 group 的所有 member 返回其 response;
- consumer 在接收到 GroupCoordinator 的 response 后,如果这个 consumer 是 group 的 leader,那么这个 consumer 将会负责为整个 group assign partition 订阅安排(默认是按 range 的策略,目前也可选 roundrobin),然后 leader 将分配后的信息以
sendSyncGroupRequest ()请求的方式发给 GroupCoordinator,而作为 follower 的 consumer 实例会发送一个空列表; - GroupCoordinator 在接收到 leader 发来的请求后,会将 assign 的结果返回给所有已经发送 sync-group 请求的 consumer 实例,并且 group 的状态将会转变为 Stable,如果后续再收到 sync-group 请求,由于 group 的状态已经是 Stable,将会直接返回其分配结果。
sync-group 发送请求核心代码如下:
1 | // 当consumer为follower时,从GroupCoordinator拉取分配结果 |
这个阶段主要是将分区分配方案同步给各个消费者,这个同步仍然是通过 GroupCoordinator 来转发的。
分区策略并非由 leader 消费者来决定,而是各个消费者投票决定的,谁的票多就采用什么分区策略。这里的分区策略是通过
partition.assignment.strategy参数设置的,可以设置多个。如果选举出了消费者不支持的策略,那么就会抛出异常IllegalArgumentException: Member does not support protocol。
经过上面的步骤,一个 consumer 实例就已经加入 group 成功了,加入 group 成功后,将会触发 ConsumerCoordinator 的 onJoinComplete () 方法,其作用就是:更新订阅的 tp 列表、更新其对应的 metadata 及触发注册的 listener。
1 | // 加入group成功 |
至此,一个 consumer 实例算是真正上意义上加入 group 成功。
然后 consumer 就进入正常工作状态,同时 consumer 也通过向 GroupCoordinator 发送心跳来维持它们与消费者组的从属关系,以及它们对分区的所有权关系。只要以正常的间隔发送心跳,就被认为是活跃的,但是如果 GroupCoordinator 没有响应,那么就会发送 LeaveGroup 请求退出消费者组。
本文参考
http://generalthink.github.io/2019/05/15/how-to-join-kafka-consumer-group/
https://matt33.com/2017/10/22/consumer-join-group/
声明:写作本文初衷是个人学习记录,鉴于本人学识有限,如有侵权或不当之处,请联系 wdshfut@163.com。